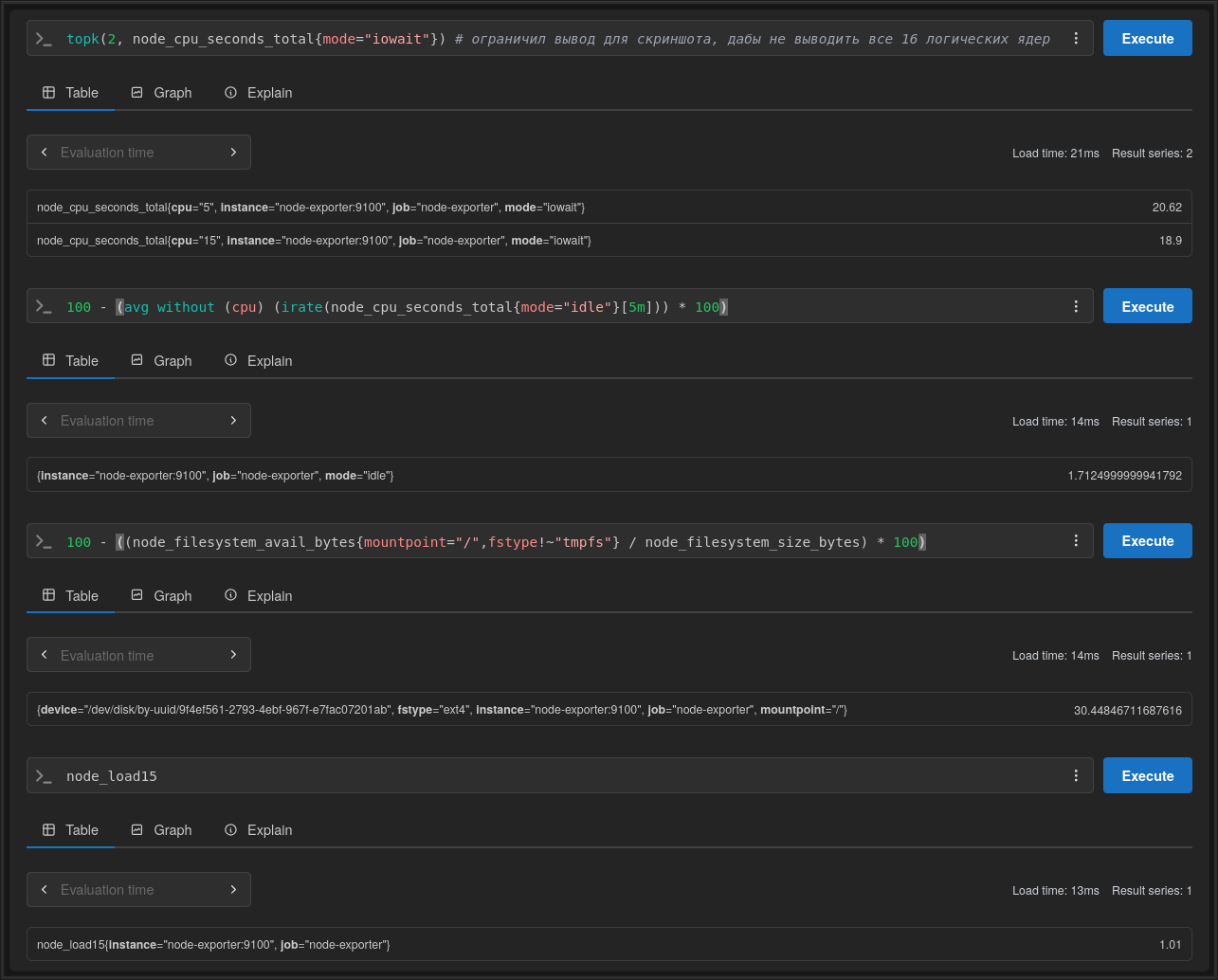
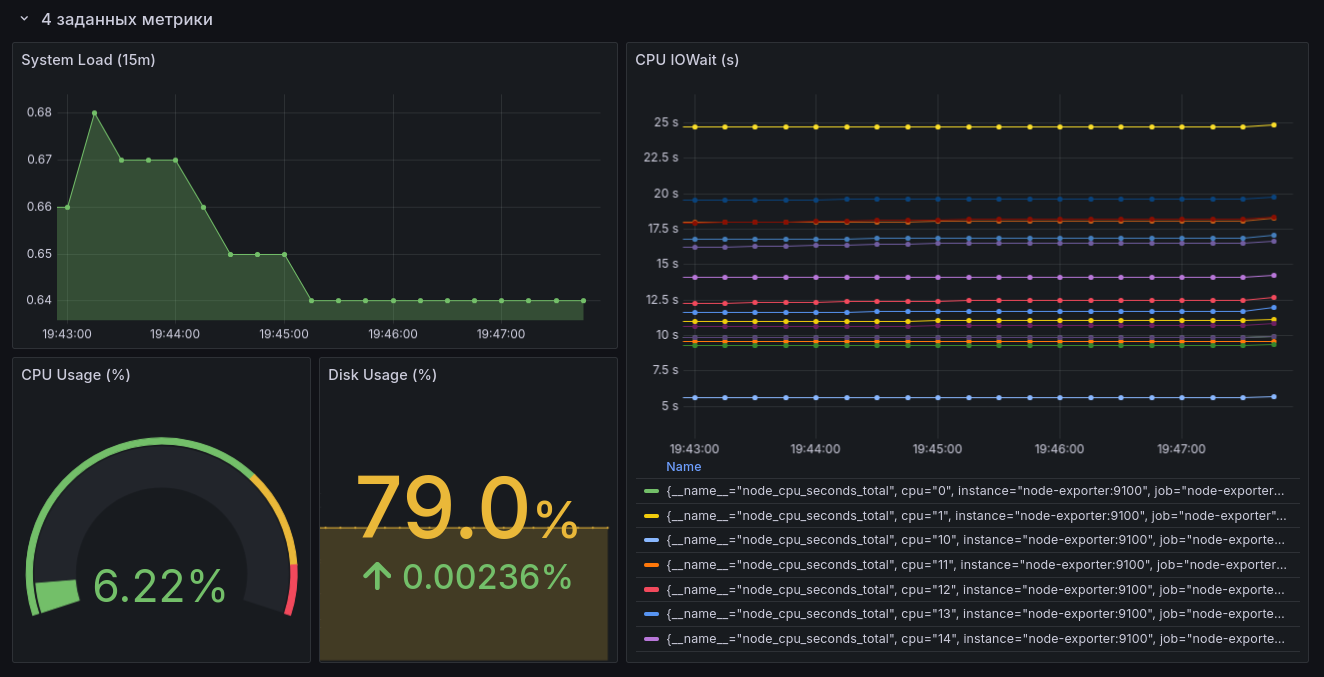
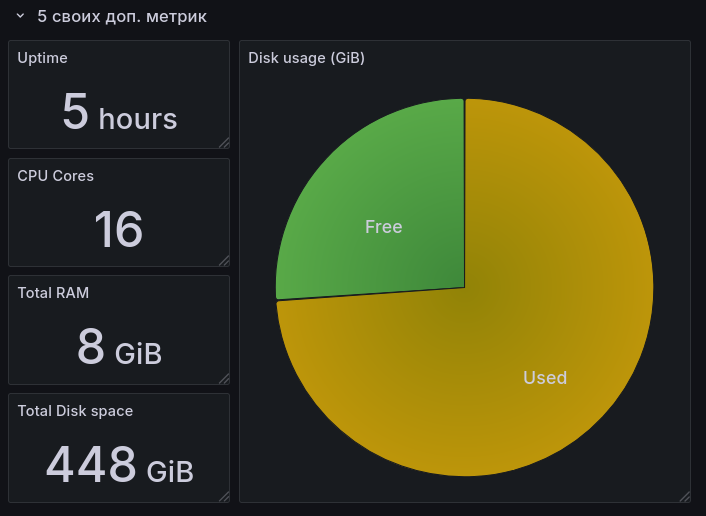
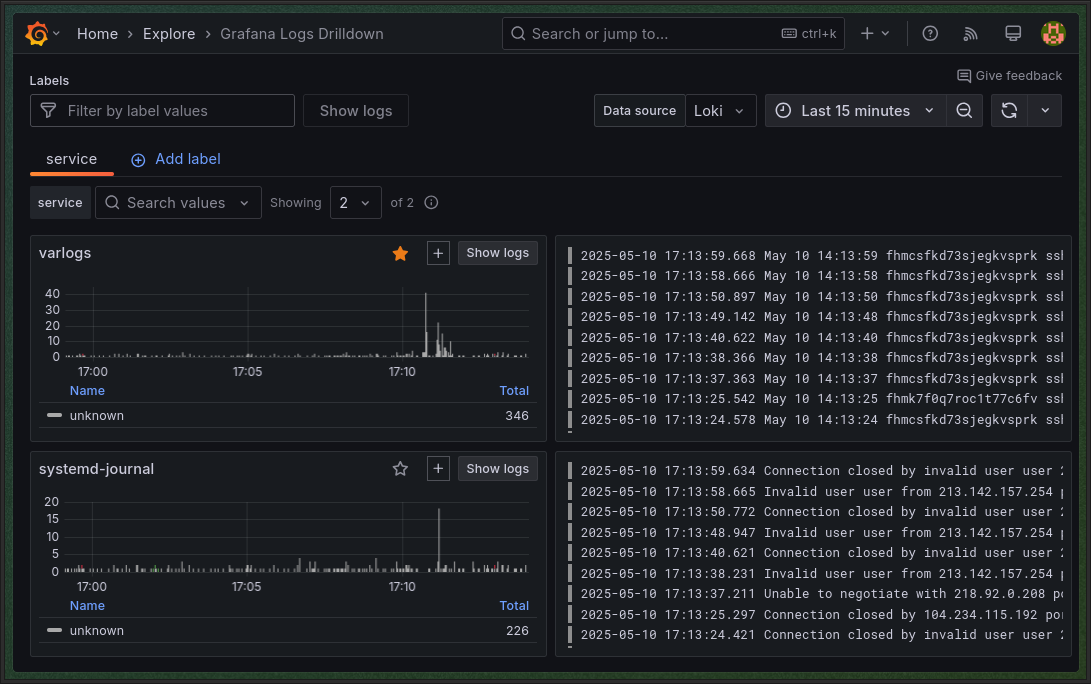
Используя Grafana, прикрутите визуализацию для всех метрик, что мы указали выше, плюсом добавьте свои, на ваш вкус и цвет. Пять штук будет вполне достаточно. Чтобы было интереснее, визуализируйте все метрики, используя Stat, Graph, Gauge, Time Series и Pie Chart. Для каких метрик что использовать — на ваше усмотрение.
Graph и Time Series
Раньше был тип визуализации “Graph”, у которого, как я понимаю, имелся формат “Time Series”, а теперь это просто одна сущность в виде типа визуализации “Time Series” — визуализации под именем “Graph” больше нет.
Использование Slideshow
В разделе “Что оценивается” требовалось “Использование Slideshow”.
Как я понял, имелись в виду плейлисты; использовать их буду в Задании 4, где будет несколько дашбордов, и, следовательно, будет в них нужда.
Dashboard
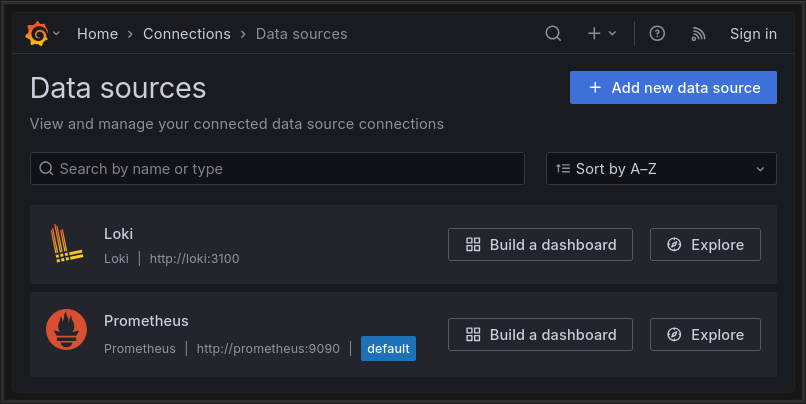
Data sources
Задание 3
Что нужно сделать
Сделайте четыре алерта:
Хост получает очень много трафика за минуту. Пусть будет выше 50 Mb/s.
groups: - name: "Main rules" rules: - alert: HighIncomingTraffic expr: sum by (instance) (rate(node_network_receive_bytes_total{device!~"lo|veth.*|docker.*"}[15s])) / (1024 * 1024) > 50 for: 15s labels: severity: warning annotations: summary: "High Incoming network Traffic" description: "Incoming network Traffic > 50 MB/s on {{ $labels.instance }}" - alert: HighCpuLoad expr: 100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[1m])) * 100) > 85 for: 5s labels: severity: warning annotations: summary: "High CPU Load" description: "CPU Load > 85% on {{ $labels.instance }}" - alert: TargetDown expr: up == 0 for: 5s labels: severity: critical annotations: summary: "Prometheus target is DOWN" description: "{{ $labels.instance }} is DOWN" - alert: AllTargetsDown expr: count by (job) (up) == 0 for: 5s labels: severity: critical annotations: summary: "All Prometheus targets are DOWN" description: "Prometheus can't find NONE of the targets"
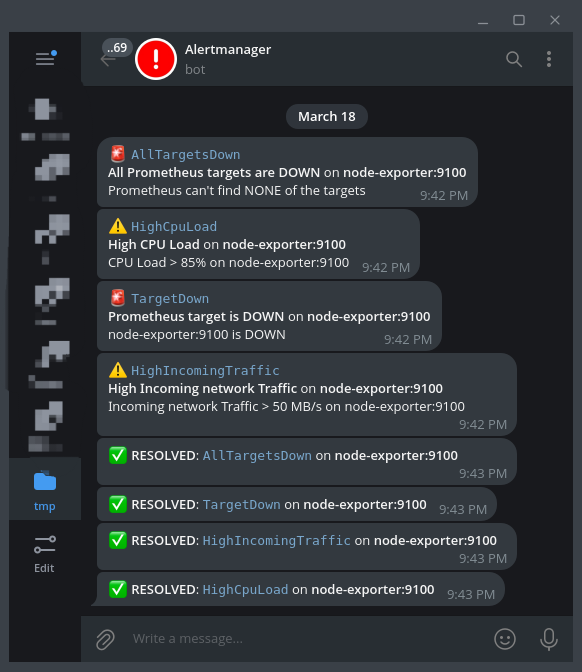
Alert messages
Алерты отправляются напрямую в telegram без посредников-сервисов.
Простой шаблон алерт-сообщений для telegram, позволяющий понять, что произошло и где это произошло:
telegram.tmpl
{{ define "telegram.message" }}{{ range .Alerts }}{{ if eq .Status "firing" }}{{ if eq .Labels.severity "critical" }}🚨 <code>{{ .Labels.alertname }}</code> {{ else }}⚠️ <code>{{ .Labels.alertname }}</code>{{ end }}<b>{{ .Annotations.summary }}</b> on <b>{{ .Labels.instance }}</b>{{ .Annotations.description }}{{ else if eq .Status "resolved" }}✅ <b>RESOLVED</b>: <code>{{ .Labels.alertname }}</code> on <b>{{ .Labels.instance }}</b>{{ end }}{{ end }}{{ end }}
Задание 4
Что нужно сделать
Пускай у нас будет условный интернет-магазин.
На первом инстансе у нас веб-приложение.
На втором — база данных.
На третьем — Prometheus, Grafana и так далее.
Разверните систему мониторинга, чтобы за всем этим делом следить.
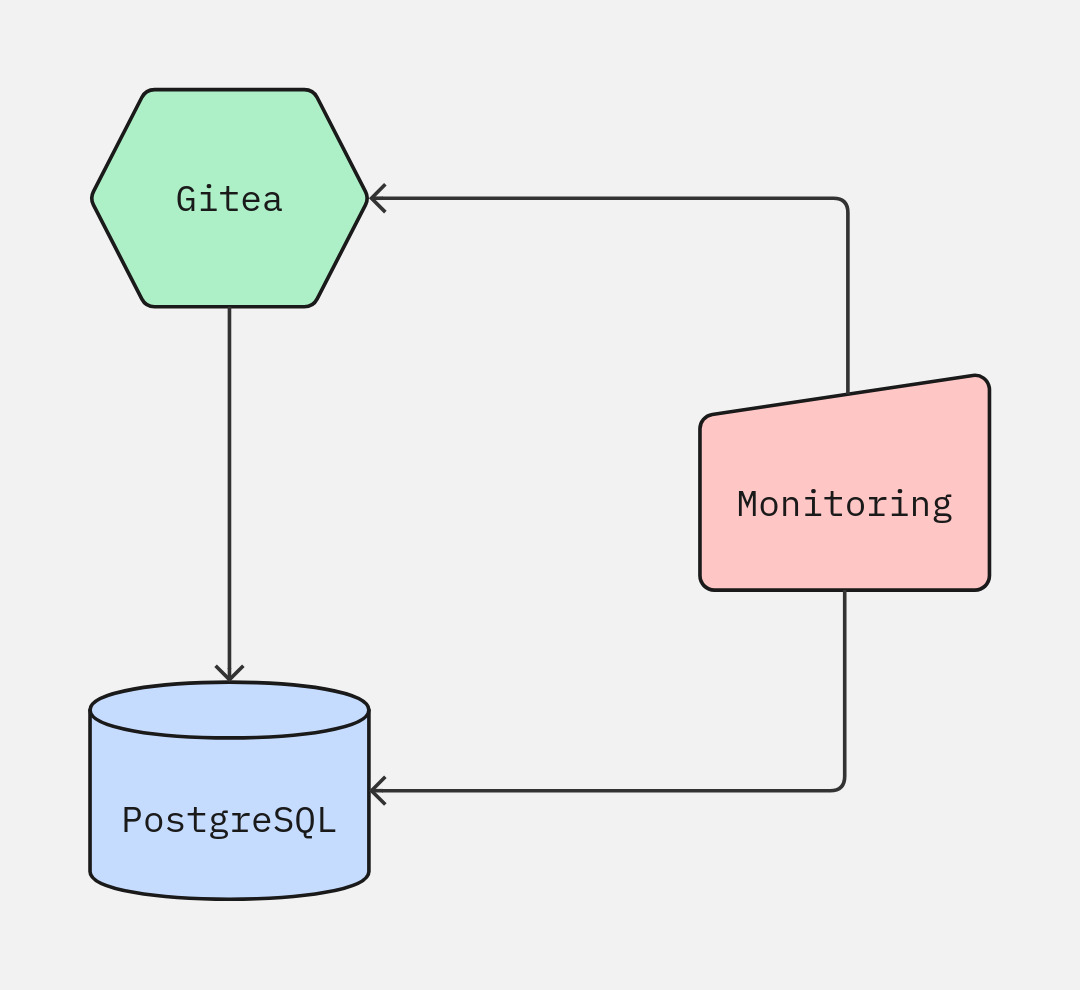
Описание инфраструктуры
На первом инстансе расположено веб-приложение (Gitea).
На втором — база данных (PostgreSQL), в которую и пишет Gitea свои данные.
На третьем — система мониторинга, следящая за всей инфраструктурой.
Разворачивание автоматизировано, поэтому terraform apply — единственное (кроме задания пары необходимых переменных), что требуется для получения готовой к работе инфраструктуры.
Terraform в итоге закончит свою работу и выдаст такой output с IP-адресами нод и URL сервисов:
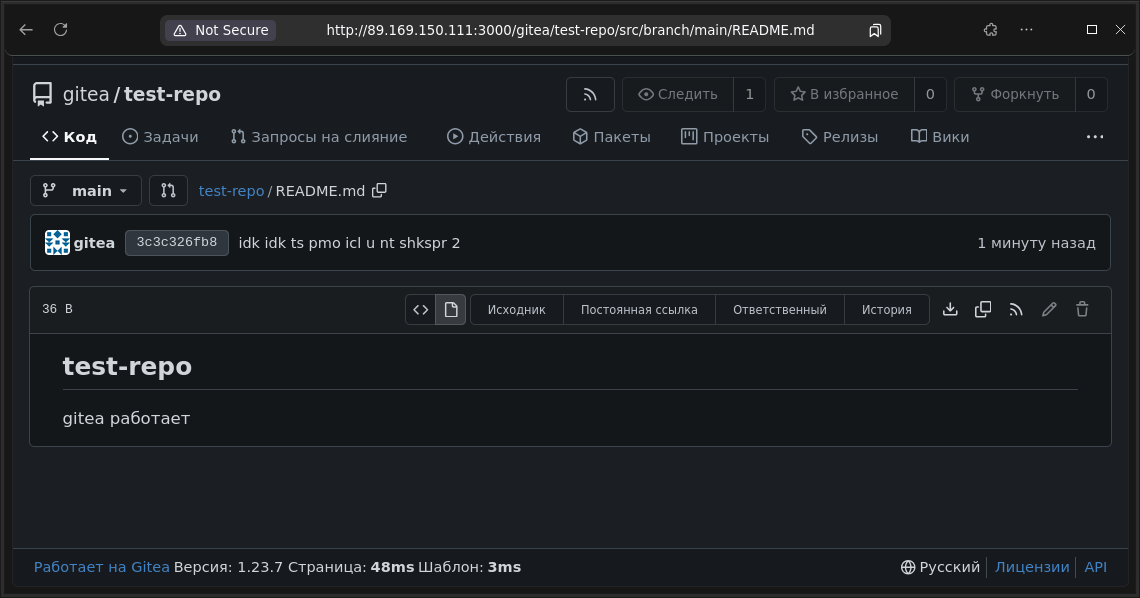
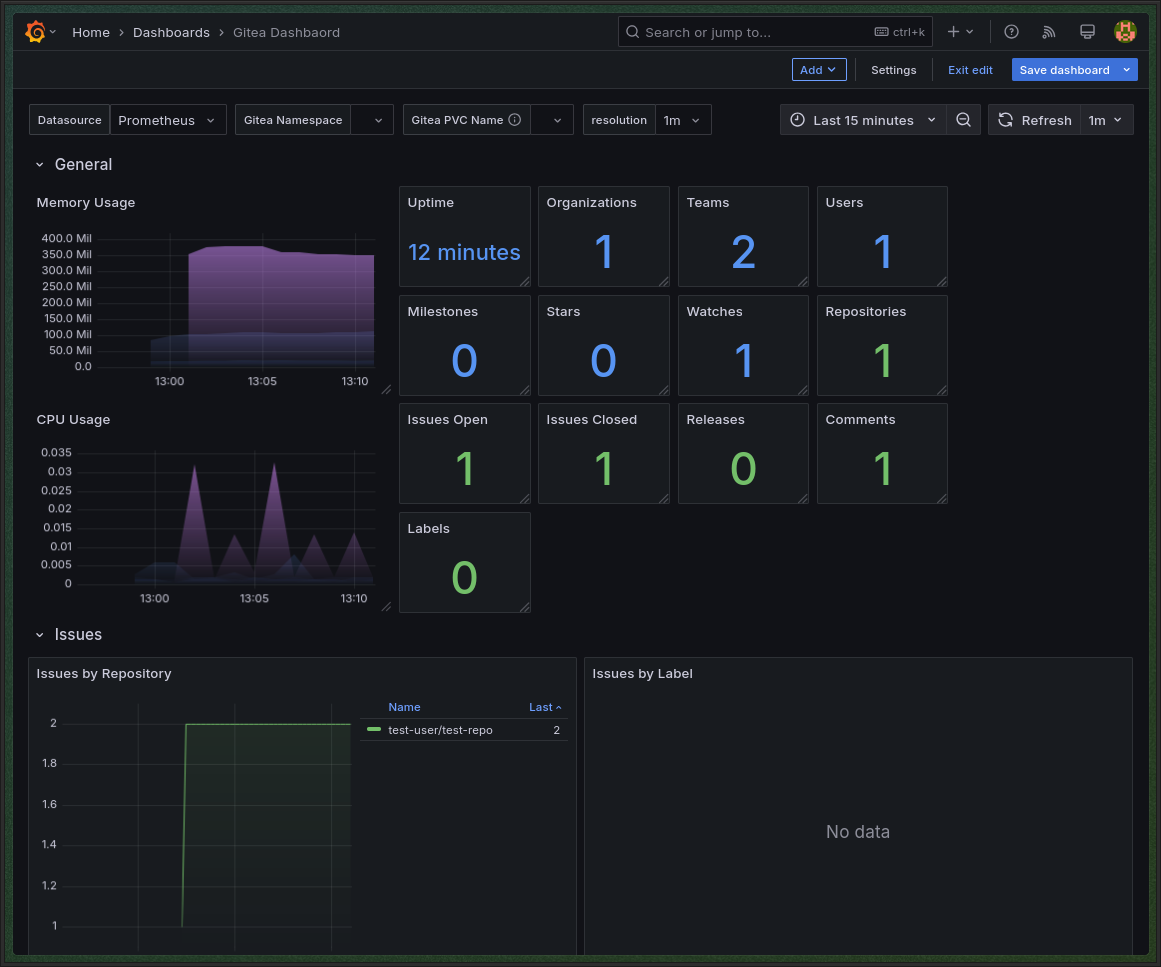
Через некоторое время сервисы поднимутся с помощью cloud-init и можно перейти по ссылке из terraform output на веб-интерфейс Gitea, например: На скриншоте выше был создан тестовый репозиторий в Gitea, чтобы показать, что сервис функционирует.
Поменяй дефолтный пароль на ВМ!
После поднятия ВМ не забудь поменять дефолтный пароль юзера admin, который указан в конфигурации cloud-init
terraform/cloud-init.template.yml:14
passwd: "changeme"
Grafana
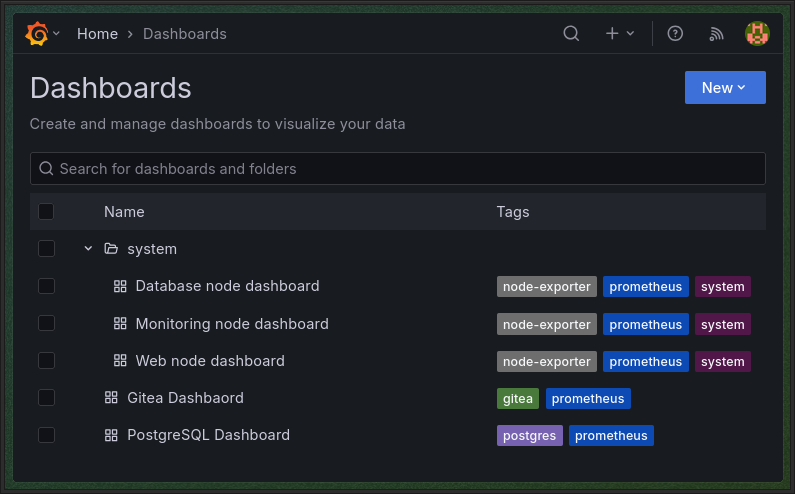
Итоговый список дашбордов:
Gitea dashboard:
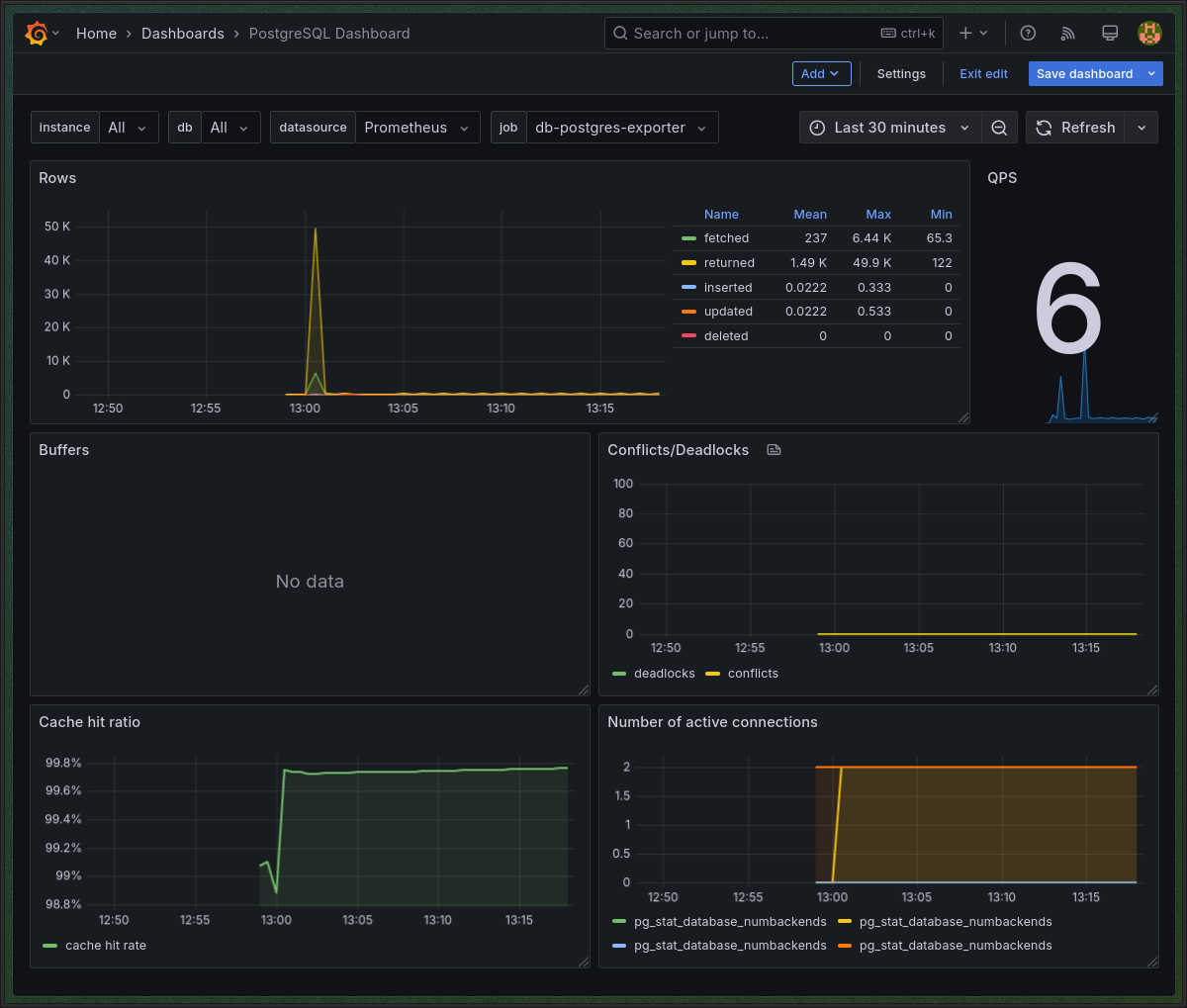
PostgreSQL dashboard:
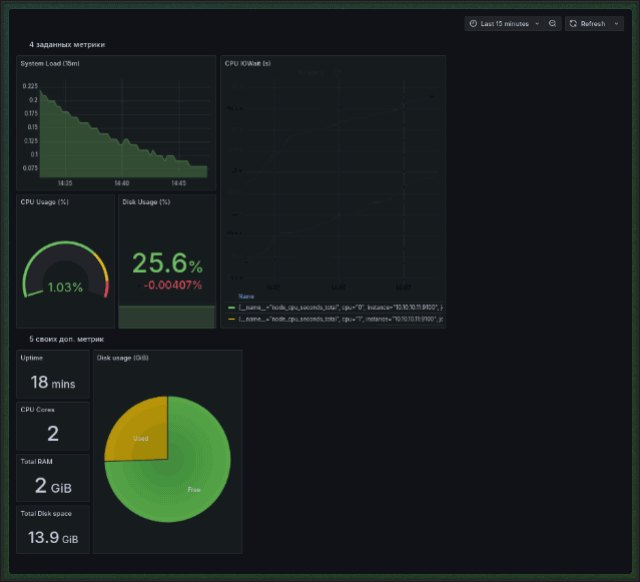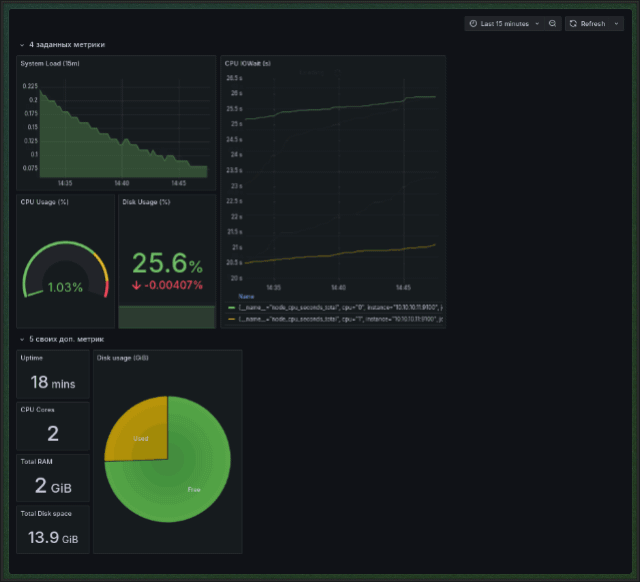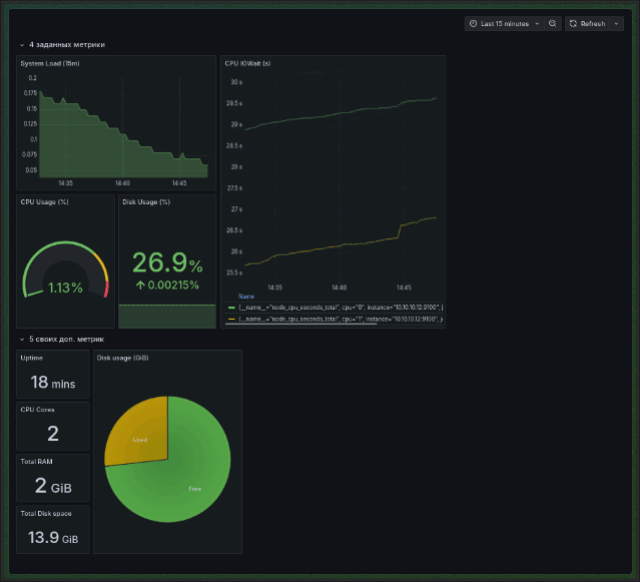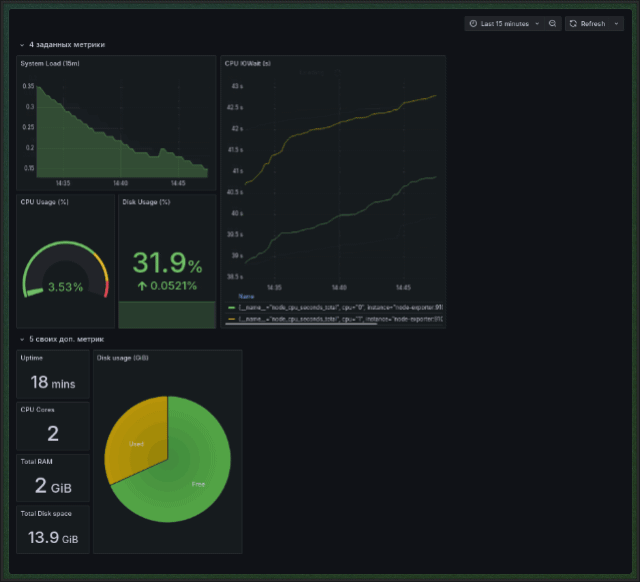
Системные (node-exporter based) дашборды для каждого инстанса в настроенном плейлисте (на гифке просто показана работа плейлиста — дашборды те же): Плейлисты в grafana не поддаются provisioning-у, поэтому в поднимаемой инфраструктуре заранее настроенных плейлистов нет — их нужно настраивать самому.
Отслеживает высокую частоту ошибок (не 200) на веб-интерфейсе Gitea. Поможет выявить проблемы с приложением / сетью до того, как конечные юзеры начнут жаловаться.
(increase(node_vmstat_oom_kill[1m]) > 0)
Срабатывает при обнаружении OOM kill-a процессов из-за нехватки памяти. Поможет избежать потери данных и сбоев приложений из-за нехватки ресурсов.
(min_over_time(node_timex_sync_status[1m]) == 0 and node_timex_maxerror_seconds >= 16)
Срабатывание указывает на проблемы с синхронизацией системных часов. Поможет избежать огромной кучи сложновыявляемых и неочевидных ошибок.
А работа связки alertmanager - telegram уже показана в третьем задании.