Множество - неупорядоченная структура данных с уникальными элементами. Как и словари, оформляются фигурными скобками, не имеют индексов.
У множеств (как и у словарей) высокая скорость поиска, гораздо выше, чем у списков.
Множество похоже на словарь, в котором значения отброшены, а оставлены только ключи. Как и в словаре, ключи должны быть уникальными.
Юзай множество, если нужно просто узнать, существует элемент в нем или нет (все остальное неважно).
>>> fs = frozenset([3, 2, 1])>>> fsfrozenset({1, 2, 3})>>> fs.add(4)Traceback (most recent call last): File "<input>", line 1, in <module> fs.add(4) ^^^^^^AttributeError: 'frozenset' object has no attribute 'add'
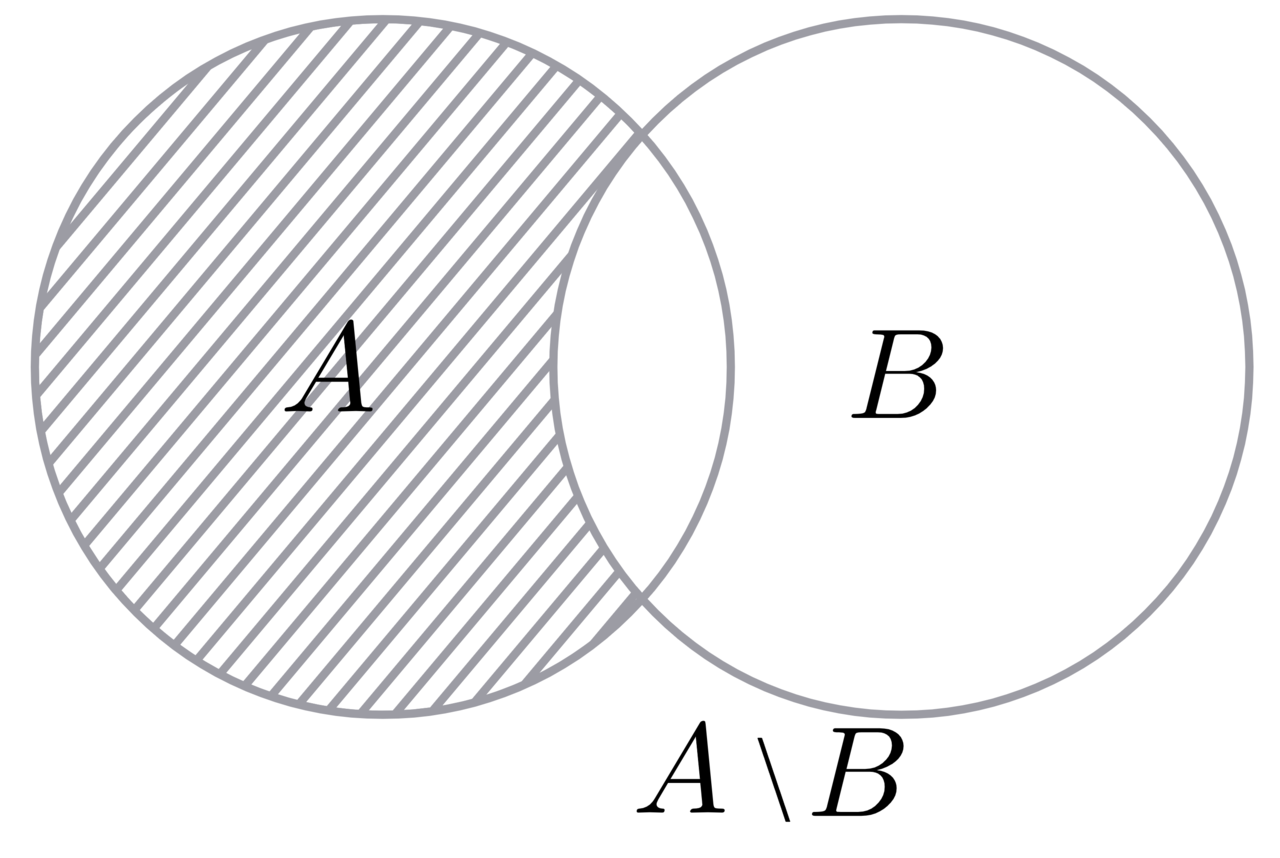
Пересечение множеств. Метод .intersection() или &
Это всё, кстати - уже алгебра.
Найти пересечение одного множества с другим можно так:
>>> a = {1, 2, 3, 4}>>> b = {3, 4, 5, 6}>>> a & b{3, 4}>>> a.intersection(b){3, 4}
Объединение множеств. Метод .union() или |
Объединить множества можно так:
>>> a = {1, 2, 3, 4}>>> b = {3, 4, 5, 6}>>> a | b{1, 2, 3, 4, 5, 6}>>> a.union(b){1, 2, 3, 4, 5, 6}
Разность множеств. Метод .difference() или -
Разностью двух множеств называется множество, состоящее из тех и только тех элементов, которые входят в первое множество, но не входят во второе.
>>> a = {1, 2, 3, 4}>>> b = {3, 4, 5, 6}>>> a - b{1, 2}>>> a.difference(b){1, 2}
Исключающее ИЛИ. Функция symmetric_difference() или оператор ^
Позволяет найти элементы или первого, или второго множества, но не общие:
>>> a = {1, 2, 3, 4}>>> b = {3, 4, 5, 6}>>> a ^ b{1, 2, 5, 6}>>> a.symmetric_difference(b){1, 2, 5, 6}
Подмножество. Функция issubset() или операторы <=, <
Позволяет проверить, является ли одно множество подмножеством другого (когда все члены первого множества являются членами второго):
>>> a = {1, 2, 3, 4}>>> b = {3, 4, 5, 6}>>> a <= bFalse>>> a.issubset(b)False
Для того чтобы стать собственным подмножеством, второе множество должно содержать все члены первого и несколько других. Определяется это с помощью оператора <:
>>> a < bFalse>>> a < aFalse
Надмножества. Функция issuperset() или операторы >=, >
Надмножество противоположно подмножеству (все члены второго множества являются также членами первого). Для определения этого используется оператор >= или функция issuperset():
>>> a = {1, 2, 3, 4}>>> b = {3, 4, 5, 6}>>> a >= bFalse>>> a.issuperset(b)False
Любое множество является надмножеством самого себя:
>>> a >= aTrue>>> a.issuperset(a)True
Можно проверить правильное надмножество (первое множество содержит все члены второго и несколько других) с помощью оператора >:
>>> a > bFalse
Множество не может быть правильным надмножеством самого себя:
>>> a > aFalse
Другие методы множеств и операции с множествами
Методы множеств
Метод
Что делает метод
nums.add(elem)
добавляет элемент в множество
nums.remove(elem)
удаляет элемент из множества. KeyError, если такого элемента не существует
nums.discard(elem)
удаляет элемент, если он находится в множестве. Если элемента нет, то ничего не происходит
nums.pop()
удаляет первый элемент из множества. Так как множества не упорядочены, нельзя точно сказать, какой элемент будет первым
nums.clear()
очистка множества
Операции со множествами
Операция
Метод
Что делает операция
A | B
A.union(B)
Возвращает множество, являющееся объединением множеств A и B
A |= B
A.update(B)
Добавляет в множество Aвсе элементы из множества B
A & B
A.intersection(B)
Возвращает множество, являющееся пересечением множеств A и B
A &= B
A.intersection_update(B)
Оставляет в множестве A только те элементы, которые есть в множестве B
A - B
A.difference(B)
Возвращает разность множеств A и B (элементы, входящие в A, но не входящие в B)
A -= B
A.difference_update(B)
Удаляет из множества A все элементы, входящие в B
Проверка наличия значения с помощью оператора in
Это самый распространенный сценарий использования множеств:
>>> drinks = { 'martini': {'vodka', 'vermouth'}, 'black russian': {'vodka', 'kahlua'}, 'white russian': {'cream', 'kahlua', 'vodka'}, 'manhattan': {'rye', 'vermouth', 'bitters'}, 'screwdriver': {'orange juice', 'vodka'}}>>> for name, contents in drinks.items(): if 'vodka' in contents: print(name)martiniblack russianwhite russianscrewdriver>>> for name, contents in drinks.items(): if 'vodka' in contents and not ('vermouth' in contents or 'cream' in contents): print(name)screwdriverblack russian
Если нужно проверить наличие сразу нескольких значений множества: допустим, нужен напиток с апельсиновым соком или вермутом. Для юзай оператор пересечения множеств &:
>>> for name, contents in drinks.items(): if contents & {'vermouth', 'orange juice'}: print(name)screwdrivermartinimanhattan
Результатом работы оператора & является множество со всеми элементами из обоих сравниваемых списков. Если ни один из заданных ингредиентов не содержится в предлагаемых коктейлях, оператор & вернет пустое множество. Этот результат можно считать равным False.
Или если нужна водка, не смешанная со сливками или вермутом:
>>> for name, contents in drinks.items(): if 'vodka' in contents and not contents & {'vermouth', 'cream'}: print(name)screwdriverblack russian
fck alcohol
Алгоритмическая сложность методов множества
Добавление элемента в множество add
средний случай: O(1)
худший случай: O(n), где n - размер множества
Худший случай происходит, когда случается коллизия хешей и требуется перехеширование и перестроение множества.
Поиск элемента в множестве in
средний случай: O(1)
худший случай: O(n), где n - размер множества
В худшем случае поиск может пройти через все элементы множества.
Удаление элемента из множества remove, discard
средний случай: O(1)
худший случай: O(n)
В худшем случае удаление может потребовать перестроения множества после завершения процесса.
Объединение множеств union
средний случай: O(min(len(set1),len(set2))) set1 и set2 - размеры двух объединяемых множеств
худший случай: O(len(set1)+len(set2))
Пересечение множеств intersection
средний случай: O(min(len(set1),len(set2)))
худший случай: O(min(len(set1),len(set2)))
Соус: Книга “Простой Python” → Глава 8. “Словари и множества”