SQL
База данных - средство хранения данных, в котором данные находятся в структурированном и легкодоступном виде.
Есть реляционные и нереляционные БД.
Реляционные БД (SQL)
(От англ. “relation” – связь.)
MySQL
PostgreSQL
MsSQL (MicrosoftSQL)
SQLite
OracleDB
Терминология
- Реляционные = SQL
- Дамп БД – Файл, в который выгружена структура и данные из базы и который можно загрузить в другую базу, что приведёт к полному восстановлению данных
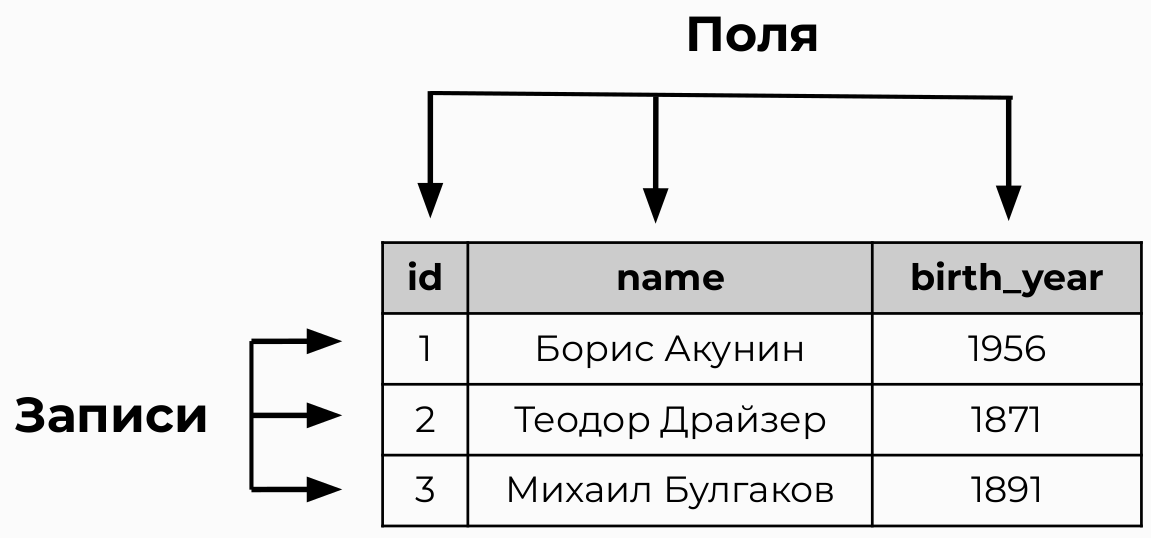
- Записи - строки
- Поля – столбцы
Значение NULL
Специальное значение, которое может быть в поле любого типа, если оно не помечено как NOT NULL
Язык запросов SQL
Structured Query Language – язык структурированных запросов.
Язык, позволяющий работать с SQL DB, в том числе добавлять в них данные, получать их, изменять и удалять их, а также управлять структурой самой БД – структурой таблиц, полей и связей между ними.
Дамп базы данных
Файл, в который выгружена структура и данные из базы и который можно загрузить в другую базу, что приведёт к полному восстановлению данных. Там по сути SQL запросы на создание базы, таблиц, добавление данных и т.п.
Нереляционные БД (NoSQL)
Не используют SQL для запросов и т.д.
Форматы хранения данных в NoSQL-базах:
- Пары “ключ - значение”
Redis
Memcached
AmazonDynamoDB - JSON-документы
mongoDB
CouchDB
elasticsearch - Семейства столбцов
- Графы и т.д.
На этом с NoSQL пока всё. Дальше идет только SQL
Типы полей (данных) в SQL DB
Числовые данные
| Тип | Мин. значение | Макс. значение |
|---|---|---|
TINYINT | $-128$ | $127$ |
INT | $-2147483647$ | $2147483647$ |
BIGINT | $-2^{63}$ | $-2^{63}-1$ |
FLOAT | $1.17*10^{-38}$ | $3.4*10^{38}$ |
DOUBLE | $2.2*10^{-308}$ | $1.8*10^{308}$ |
Данные о дате и времени
| Типа | Формат | Годы (от и до) |
|---|---|---|
DATE | YYYY-MM-DD | 1000 - 9999 |
DATETIME | YYYY-MM-DD HH:MM:SS | 1000 - 9999 |
TIMESTAMP | YYYY-MM-DD HH:MM:SS | 1970 - 2038-01-19 |
Строковые данные
| Тип | Максимальная длина |
|---|---|
CHAR(N) | 255 |
VARCHAR(N) | 255 / 65535 |
TINYTEXT | 255 |
TEXT | 65535 |
MEDIUMTEXT | 16777215 (16Mb) |
LONGTEXT | 4 Gb |
Пространственные данные
Представляют сведения о физическом расположении и форме геометрических объектов. Этими объектами могут быть точки расположения или более сложные объекты, такие как страны/регионы, дороги или озера.
JSON-данные
JSON 🤷♂️
Типы связей в SQL DB
Связь типа one-to-many (один ко многим)
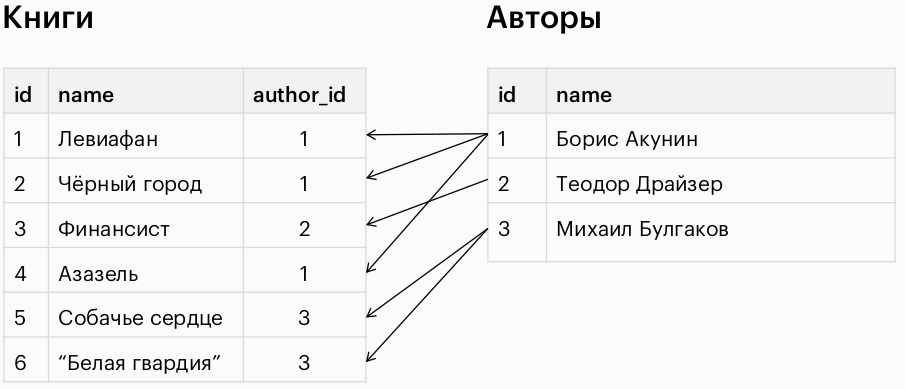
Либо в одной таблице:
Связь типа one-to-one (один к одному)
Редкая достаточно штука:
Связь типа many-to-many (многие ко многим)
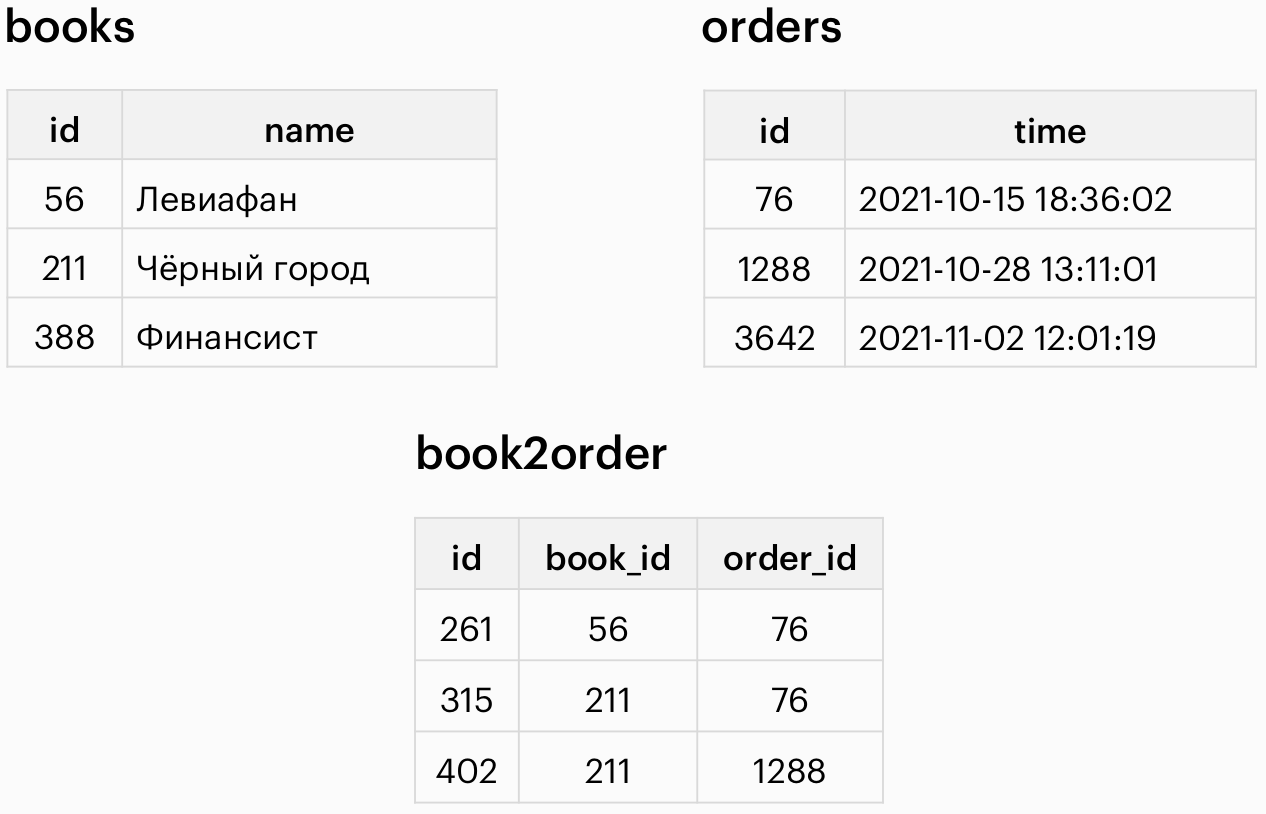
Таблица book2order используется для связывания таблиц book и order.
SELECT-запросы
Синтаксис на простом примере
SELECT * FROM tableName;Вывод отдельных полей таблицы
SELECT field1, field2
FROM tableName;Изменение имён полей в запросах
SELECT
field1 AS f1,
field2 AS f2
FROM tableName;Запись ниже эквивалента верхней - можно и не использовать AS.
SELECT
field1 f1,
field2 f2
FROM tableName;Изменение данных в SELECT-запросах
SELECT
(field1 + field2) total
FROM tableName;Фильтрация данных
Равенство числу
SELECT `id`, `name`
FROM `good`
WHERE `count` = 0Числа больше или меньше
SELECT `id`, `name`
FROM `good`
WHERE `count` <= 50Строка и неравенство
SELECT *
FROM `order_status`
WHERE `code` != 'NEW'Даты
SELECT `id`, `name`, `reg_date`
FROM `user`
WHERE `reg_date` >= '2019-01-01'| Тип | Формат | Пример |
|---|---|---|
| Дата | YYYY-MM-DD | 2021-01-30 |
| Дата и время | YYYY-MM-DD HH:MM:SS | 2021-01-30 22:45:07 |
Диапазон дат и времени
SELECT * FROM `user`
WHERE
`reg_date` >= '2021-09-08 00:00:00'
AND
`reg_date` <= '2021-09-08 23:59:59'SELECT * FROM `user`
WHERE `reg_date` BETWEEN
'2021-09-08 00:00:00' AND
'2021-09-08 23:59:59'Оператор WHERE и сложные условия
Оператор LIKE
SELECT *
FROM `good_category`
WHERE `name` LIKE 'Чай'Маски:
| Маска | Значение |
|---|---|
% | 0 или более символов |
_ | один символ |
SELECT *
FROM `good_category`
WHERE `name` LIKE '%чай%'id | parent_id | name |
|---|---|---|
| 1 | NULL | Чай |
| 6 | 1 | Белый чай |
| 7 | 1 | Ароматизированные чай |
| 8 | 1 | Черный чай |
| 9 | 1 | Зеленый чай |
| 12 | 1 | Чай для детей |
| 13 | 1 | Связанные чай |
| 15 | 1 | Чай в шелке |
Сравнение с NULL
id | parent_id |
|---|---|
| 1 | -10 |
| 2 | 0 |
| 3 | NULL |
| 4 | 35 |
SELECT *
FROM `good_category`
WHERE `parent_id` IS NULLРезультат:
id | parent_id |
|---|---|
| 3 | NULL |
SELECT *
FROM `good_category`
WHERE `parent_id` IS NOT NULLРезультат:
id | parent_id |
|---|---|
| 1 | -10 |
| 2 | 0 |
| 4 | 35 |
Объединение нескольких условий
SELECT *
FROM `good_category`
WHERE
`name` LIKE '%чай%' AND
`parent_id` IS NOT NULLПримеры:
| Условие | Пример |
|---|---|
LIKE '% чай %' | Зелёный чай с мятой |
LIKE '% чай' | Белый чай Зеленый чай NOT Молочай |
LIKE 'чай %' | Чай с вишней NOT Чайник |
Одно из условий (оператор OR)
SELECT *
FROM `good_category`
WHERE
`name` LIKE '% чай %' OR
`name` LIKE 'чай %' OR
`name` LIKE '% чай'SELECT * FROM `order`
WHERE
`status_id` = 7 OR
`status_id` = 8Группа значений (оператор IN)
SELECT * FROM `order`
WHERE `status_id` IN (7, 8)Разные условия (c круглыми скобками)
SELECT *
FROM `good_category`
WHERE
(`name` LIKE '% чай %' OR
`name` LIKE 'чай %' OR
`name` LIKE '% чай') AND
`parent_id` IS NOT NULLSELECT *
FROM `good_category`
WHERE
`name` LIKE '% чай %' OR
`name` LIKE 'чай %' OR
(`name` LIKE '% чай' AND
`parent_id` IS NOT NULL)Сортировка и ограничение кол-ва результатов
Сортировка по возрастанию (два эквивалентных запроса)
SELECT *
FROM `good`
ORDER BY `name`SELECT *
FROM `good`
ORDER BY `name` ASCСортировка по убыванию
SELECT *
FROM `good`
ORDER BY `name` DESCМножественная сортировка
SELECT *
FROM `good`
ORDER BY
`category_id`,
`name`Ограничение количества записей
SELECT *
FROM `good`
LIMIT 100Запись с наибольшим значением
SELECT *
FROM `good`
ORDER BY `price` DESC
LIMIT 1LIMIT со сдвигом
SELECT *
FROM `good`
LIMIT 10, 20Оператор LIMIT
Сдвиг 10
Запятая ,
Кол-во элементов 20
В SQL счет начинается с 1, а не с 0, как в ЯП.
Объединение таблиц, JOIN-ы
SELECT
`good_category`.`name`,
`good`.`name`
FROM `good`
JOIN `good_category` ON
`good_category`.`id` =
`good`.`category_id`По сути JOIN присоединяет две таблицы в одну, это можно наглядно увидеть если SELECT-ить всё (*)
При присоединении нужно прописать точки присоединения после оператора ON
Результат:
| name | name |
|---|---|
| Дарджилинг | Дарджилинг Джиель |
| Айс Ти | Айс Ти “Инжирный персик” |
| Айс Ти | Айс Ти “Черничный Прованс” |
| Айс Ти | Айс Ти “Сочное манго” |
| Айс Ти | Айс Ти “Клубничный зефир” |
| Айс Ти | Айс Ти “Апельсиновый лед” |
| Айс Ти | Айс Ти “Карамельное яблоко” |
| Айс Ти | Айс Ти “Инжирный персик” |
| Айс Ти | Айс Ти “Черничный Прованс” |
| Айс Ти | Айс Ти “Сочное манго” |
| Айс Ти | Айс Ти “Клубничный зефир” |
И в SELECT-ах лучше давать имена полям. Можно и таблицам давать алиасы, это хорошая практика. Вот хороший пример:
SELECT
c.`name` categoryName,
g.`name` goodName
FROM `good` g
JOIN `good_category` c ON
c.`id` = g.`category_id`Типы объединений
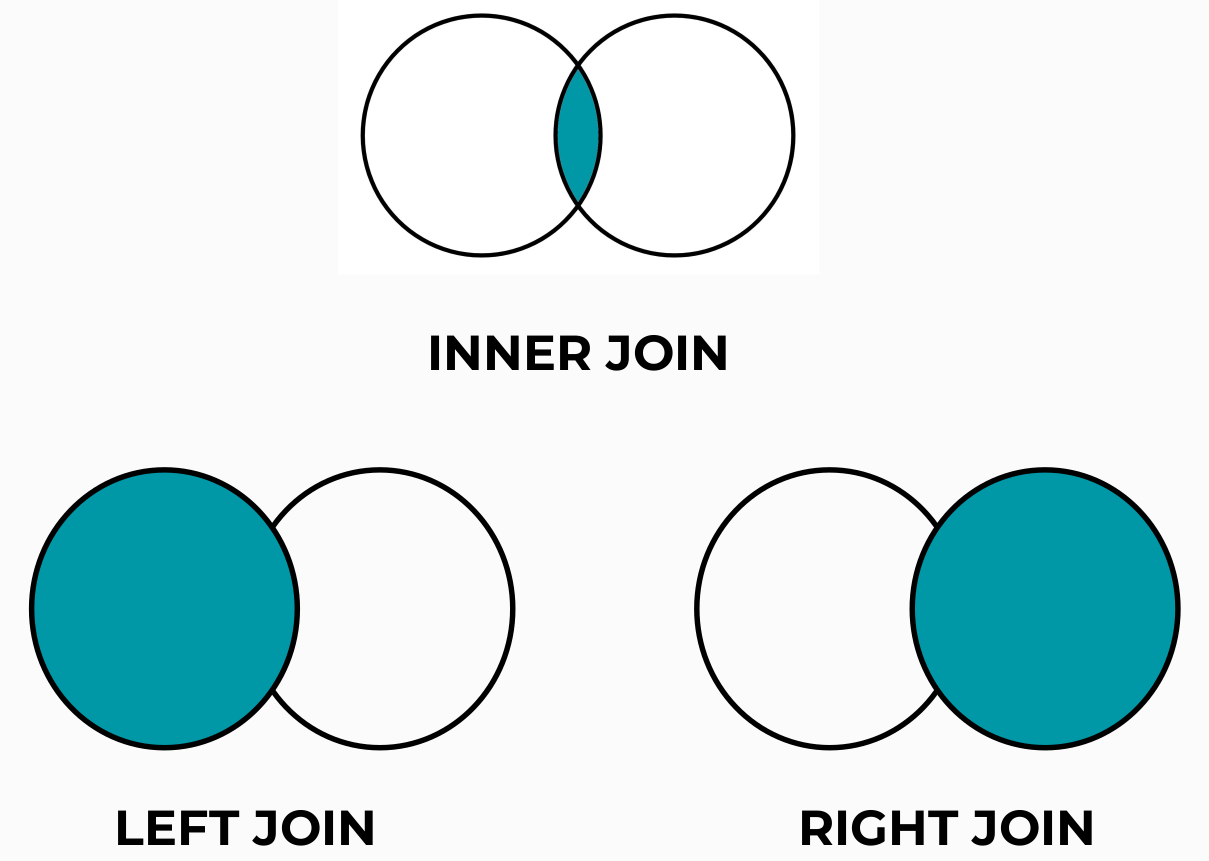
Это основные JOIN-ы.
INNER JOIN стоит по дефолту.
LEFT JOIN - это абсолютно всё из левой таблицы, плюс то, что нашлось в правой (то, что удовлетворяет выражению ON). Если не нашлось в правой, то напротив записи из левой будет NULL
RIGHT JOIN - наоборот
FULL JOIN - всё вместе
JOIN-ы пишутся прямо так, как и называются. Можно писать и INNER JOIN вместо обычного. А с LEFT/RIGHT JOIN-ами нужно писать полностью, естественно.
Фильтрация по уникальности и группировка записей
Синтаксис запроса
SELECT DISTINCT `status_id`
FROM `order`Выведет только уникальные записи в поле status_id
Уникальность по нескольким полям
SELECT DISTINCT
`src_status_id`,
`dst_status_id`
FROM `order_status_change`Тоже самое применяется на несколько полей.
Troubleshoot
В MySQL CLI есть проблема с ONLY_FULL_GROUP_BY, с которым не работает оператор GROUP BY. Чтобы отключить его, нужно ввести следующий запрос:
SET GLOBAL sql_mode=(SELECT REPLACE(@@sql_mode,'ONLY_FULL_GROUP_BY',''));И перезайти в mysql. Ответ нашел на stackoverflow по запросу “How to disable ONLY_FULL_GROUP_BY. Ответ на SO
Группировка результатов
SELECT
`src_status_id`,
`dst_status_id`
FROM `order_status_change`
GROUP BY `src_status_id`Выведет уникальные src_status_id и все dst_status_id которые есть у первого.
src_status_id | dst_status_id |
|---|---|
| 1 | 8 |
| 2 | 3 |
| 3 | 4 |
| 4 | 5 |
| 5 | 6 |
| 6 | 7 |
GROUP BY по сути почти то же самое, что и DISTINCT, но с помощью GROUP BY можно посчитать кол-во вхождений, например, то есть, можно использовать агрегатные функции.
SELECT
`category_id`,
COUNT(*)
FROM `good`
GROUP BY `category_id`
LIMIT 5LIMIT ставил, ибо таблица большая получается. Результат:
category_id | COUNT(*) |
|---|---|
| 2 | 1 |
| 3 | 480 |
| 4 | 6 |
| 5 | 84 |
| 6 | 84 |
Можно группировать по нескольким полям:
SELECT *
FROM `order_status_change`
GROUP BY
`src_status_id`,
`dst_status_id`Объединение результатов, оператор UNION
Задача - выбрать заказы, которые:
- Находятся в статусах “NEW” и “APPROVED_BY_STOCK”
- Создатели которых зарегистрировались в феврале 2018-го
- В которых есть любой йогурт
Все эти условия можно выполнить отдельными запросами и получив отдельные таблицы:
SELECT *
FROM `order` o
JOIN `order_status` s ON
s.`id` = o.`status_id`
WHERE s.`code`
IN('APPROVED_BY_STOCK', 'PACKED')SELECT *
FROM `order` o
JOIN `user` u ON u.`id` = o.`user_id`
WHERE u.reg_date BETWEEN
'2018-02-01' AND '2018-02-28'SELECT *
FROM `good` g
JOIN `order2good` o2g ON
o2g.`good_id` = g.`id`
JOIN `order` o ON o.`id` = o2g.`order_id`
WHERE g.`name` LIKE '%йогурт%'Все эти таблицы можно соединить оператором UNION, который будет стоять между запросами:
SELECT o.`id`, o.`creation_date`
FROM `order` o
JOIN `order_status` s ON
s.`id` = o.`status_id`
WHERE s.`code`
IN('APPROVED_BY_STOCK', 'PACKED')
UNION
SELECT o.`id`, o.`creation_date`
FROM `order` o
JOIN `user` u ON u.`id` = o.`user_id`
WHERE u.reg_date BETWEEN
'2018-02-01' AND '2018-02-28'
UNION
SELECT o.`id`, o.`creation_date`
FROM `good` g
JOIN `order2good` o2g ON
o2g.`good_id` = g.`id`
JOIN `order` o ON o.`id` = o2g.`order_id`
WHERE g.`name` LIKE '%йогурт%'Запросы INSERT, UPDATE и DELETE
Добавление данных, оператор INSERT
INSERT INTO `good` (
`id`,
`category_id`,
`name`,
`count`,
`price`
)
VALUES (
2088,
'6',
'Белый чай с вишней',
'50',
'344'
);Если в VALUES не прописать значение для какого-то поля, который прописан после INSERT, то будет значение по умолчанию. Но при NOT NULL если не указать значение – будет ошибка.
Для id задают AUTO_INCREMENT, который позволяет при INSERT-е не задавать не задавать само поле id и его значение, ибо AUTO_INCREMENT сам задает id нужное значение (+1)
То есть, можно и так(без id):
INSERT INTO `good` (
`category_id`,
`name`,
`count`,
`price`
)
VALUES (
'6',
'Белый чай с вишней',
'50',
'344'
);Множественная вставка записей
INSERT INTO `tbl` (`name`, `price`)
VALUES ('Белый чай', '269'),
('Красный чай', '400'),
('Зелёный чай', '204');Запросы изменения данных в записях
UPDATE `good` SET
`name` = 'Конфета'
WHERE `id` = 1055;Посложнее:
UPDATE `order` SET
`user_id` = NULL,
`status_id` = 1
WHERE
`user_id` > 10 AND
`user_id` < 50 AND
`creation_date` > '2019-01-01';Запросы удаления записей из таблицы
DELETE FROM `good`
WHERE `id` = 1373;Понятие выражения и функции в SQL-запросах
Выражения
id | category_id | name | count | price |
|---|---|---|---|---|
| 851 | 21 | Бразилия | 481 | 597 |
| 852 | 20 | Капучино Марагоджип | 140 | 587 |
| 853 | 20 | Кофе для свидания Марагоджип | 37 | 587 |
SELECT
`name`,
`price` * `count` AS cost
FROM `good`;Результат:
name | cost |
|---|---|
| Бразилия | 287157 |
| Капучино Марагоджип | 82180 |
| Кофе для свидания Марагоджип | 21719 |
SELECT
`id`,
`name`,
IF(
`count` >= 100,
'ENOUGH',
'NOT_ENOUGH'
) isEnough
FROM `good`Функции
SELECT
`category_id`,
COUNT(*) `count`
FROM `good`
GROUP BY `category_id`Выведет category_id и кол-во записей с ним:
category_id | count |
|---|---|
| 2 | 1 |
| 3 | 480 |
| 4 | 6 |
| 5 | 84 |
| 6 | 84 |
| 7 | 125 |
| 8 | 10 |
| 9 | 7 |
Можно сделать то же самое, но с уникальными name (если они повторяются):
SELECT
`category_id`,
COUNT(DISTINCT `name`), `count`
FROM `good`
GROUP BY `category_id`COUNT - агрегатная функция. Есть еще функции работы со строками, с датами, временем и другие функции.
Условные операторы и булевы выражения
Оператор IF
Синтаксис:
IF(
Выражение с условием,
Значение, если условие выполняется,
Значение, если условие не выполняется (по сути это else)
) colNameПример:
SELECT
`id`,
`name`,
IF(
`count` < 20,
`price` * 0.8,
`price`
) `price`
FROM `good`Условия с NULL
SELECT
`id`,
`name`,
IF(
`parent_id` IS NULL,
'YES',
'NO'
) `is_root`
FROM `good`Результат будет таким:
id | parent_id | name | is_root |
|---|---|---|---|
| 1 | NULL | Чай | YES |
| 2 | 1 | Дарджиллинг | NO |
| 3 | 1 | Айс Ти | NO |
| 4 | 1 | Пуэр | NO |
| 5 | 1 | Улун | NO |
| 6 | 1 | Белый чай | NO |
| 7 | 1 | Ароматизированный чай | NO |
| 8 | 1 | Черный чай | NO |
| 9 | 1 | Зеленый чай | NO |
Объединение нескольких условий
SELECT
`id`,
`name`,
IF(
`count` < 20 OR `count` > 500,
`price` * 0.8,
`price`
) `price`
FROM `good`Скобки в условиях
SELECT
`id`,
`name`,
IF(
(`count` < 20 OR `count` > 500)
AND `price` > 600,
`price` * 0.8,
`price`
) `price`
FROM `good`При наличии нескольких условий лучше обернуть их скобками - так запрос станет более читаемым.
Вложенные операторы IF
SELECT
`id`,
`name`,
IF(
`count` < 20,
'Мало',
IF(
`count` > 500,
'Много',
'Нормально'
)
) `count`
FROM `good` WHERE 1Вместо вложенных условий лучше использовать оператор CASE.
Оператор CASE
SELECT
`id`,
`name`,
CASE
WHEN `count` < 20 THEN 'Мало'
WHEN `count` > 500 THEN 'Много'
ELSE 'Нормально'
END `count`
FROM `good` WHERE 1Same IF по синтаксису, но нет скобок, запятых и в конце будет оператор END
Функции работы со строками
Длина строки
SELECT
`id`,
`name`,
CHAR_LENGTH(`name`) `length`
FROM `good`Функция
CHAR_LENGTH()просто выведет кол-во символов в строке.
Подстрока
Синтаксис:
SUBSTRING(str, start, length)
# или
SUBSTR(str, start, length)Пример:
SUBSTRING('кофе', 2, 2)
# Результат:
# офSELECT
`id`,
SUBSTR(`name`, 1, 20) `name`
FROM `good`Результат:
id | name |
|---|---|
| 1 | Айс Ти “Инжирный пер |
| 2 | Айс Ти “Черничный Пр |
| 3 | Айс Ти “Сочное манго |
| 4 | Айс Ти “Клубничный з |
| 5 | Айс Ти “Апельсиновый |
| 6 | Айс Ти “Карамельное |
| 7 | Мао Се |
Конкатенация
Синтаксис:
CONCAT(exp1, exp2, exp3, ...)Предыдущий результат выглядит некрасиво, ибо резко обрываются строки. Можно добавить ”…” к концу строк:
SELECT
`id`,
IF(
CHAR_LENGTH(`name`) > 20,
CONCAT(SUBSTR(`name`, 1, 20), '...'),
`name`
) `name`
FROM `good`id | name |
|---|---|
| 1 | Айс Ти “Инжирный пер… |
| 2 | Айс Ти “Черничный Пр… |
| 3 | Айс Ти “Сочное манго… |
| 4 | Айс Ти “Клубничный з… |
| 5 | Айс Ти “Апельсиновый… |
| 6 | Айс Ти “Карамельное … |
| 7 | Мао Се |
Конкатенация при группировке
Задача: получить что-то такое:
id | products |
|---|---|
| 1 | Молочный улун, Кофе с корицей |
| 2 | Капучино апельсиновое, Какао |
| 3 | Шоколад молочный, Зеленый чай, Капучино |
| … | … |
SELECT
o.id,
GROUP_CONCAT(g.name SEPARATOR ', ') products
FROM `order` o
JOIN `order2good` o2g ON
o2g.order_id = o.id
JOIN `good` g ON
g.id = o2g.good_id
GROUP BY o.id
SEPARATOR ', 'стоит добавить в GROUP_CONCAT, иначе в часто результате после запятых не будет пробелов никаких.
Результат:
id | products |
|---|---|
| 1 | Mao Ce |
| 2 | Итальянская смесь |
| 3 | Айс Ти «Апельсиновый лед» |
| 4 | Айс Ти «Черничный Прованс» |
| 5 | Эфиопия Иргачиф Коке Фармс Органик |
| 6 | Для нее, Мaо Се |
| 7 | Айс Ти «Сочное манго», Айс Ти «Черничный Прованс» |
| 8 | Кленовый сироп |
| 9 | Айс Ти «Клубничный зефир» |
| 10 | Волшебный лес |
| 11 | Спасибо, Айс Ти «Апельсиновый лед» |
| 12 | Айс Ти «Сочное манго», Айс Ти «Клубничный зефир», Бай Ча Цзингу, Нуга с обсыпкой «Аравия» |
| 13 | Айс Ти «Апельсиновый лед» |
| 14 | Айс Ти «Карамельное яблоко» |
| 15 | Драже «Мускат Голд» |
| 16 | Айс Ти «Карамельное яблоко», Бай Ча Цзингу |
| 17 | Айс Ти «Апельсиновый лед» |
| 18 | Айс Ти «Клубничный зефир» |
| 19 | Бай Ча Цзингу, Айс Ти «Инжирный персик», Айс Ти «Черничный Прованс» |
Удаление пробелов по краям строки
На 12-й строке можно заметить пробел и до запятой, ибо так бывает, если в конце строки стоит пробел. Можно убрать его функцией TRIM
Синтаксис прост:
TRIM(str)Прошлый запрос, но теперь с TRIM
SELECT
o.id,
GROUP_CONCAT(
TRIM(g.name) SEPARATOR ', '
) products
FROM `order` o
JOIN `order2good` o2g ON
o2g.order_id = o.id
JOIN `good` g ON
g.id = o2g.good_id
GROUP BY o.idЗамена подстрок
Синтаксис:
REPLACE(field, from, to)Чтобы, например, заменить угловые кавычки на вертикальные, нужно:
SELECT
id,
REPLACE(
REPLACE(`name`, '«', '"'),
'»',
'"'
) `name`
FROM `good`Сначала выполняется внутренний REPLACE, и внешний берет, как исходник, результат внутренней выполненной REPLACE.
Похоже на работу с пайпами в bash.
Функции работы с датами
Форматы даты и времени
![[#Типы полей (данных) в SQL DB#Данные о дате и времени]]
Функция DATE_FORMAT
Синтаксис:
DATE_FORMAT(field, format)| Обозначение | Значение |
|---|---|
%d | День месяца (от 01 до 31) |
%m | Месяц (от 01 до 12) |
%Y | Год (4 цифры) |
%H | Часы (от 00 до 23) |
%i | Минуты (от 00 до 59) |
%s | Секунды (от 00 до 59) |
%w | День недели (0 - ВС, 6 - СБ) |
%j | День в году (001 - 366) |
| … | … |
| Как сделать формат таким? |
06.12.2020
Решение:
DATE_FORMAT(field, '%d.%m.%Y')SELECT
`id`,
DATE_FORMAT(
`creation_date`,
'%d.%m.%Y'
) creationDate
FROM `order`Результат:
id | creationDate |
|---|---|
| 1 | 06.05.2015 |
| 2 | 06.04.2020 |
| 3 | 01.01.2001 |
Можно узнать кол-во заказов по месяцам:
SELECT
DATE_FORMAT(
creation_date,
'%m'
) `month`,
COUNT(*) `count`
FROM `order`
GROUP BY `month`
ORDER BY `month`month | count |
|---|---|
| 01 | 136 |
| 02 | 132 |
| 03 | 146 |
| … | … |
Функции вывода свойств даты
DAYOFWEEK(date)
DAYOFYEAR(date)
# и тдПрошлую задачу можно решить и с днями недели:
SELECT
DAYOFWEEK(creation_date) `day`,
COUNT(*) `count`
FROM `order`
GROUP BY `day`
ORDER BY `day`month | count |
|---|---|
| 1 | 280 |
| 2 | 298 |
| 3 | 285 |
| 4 | 303 |
| 5 | 291 |
| 6 | 272 |
| 7 | 290 |
Получение текущих даты и времени
NOW()
CURDATE()Это полезно при INSERT-запросах, например, для даты регистрации пользователя.
INSERT INTO `user`(
`name`,
`email`,
`password`,
`reg_date`)
VALUES (
'Дмитрий Петров',
'petrov@offstyle.com',
'b2974ddcf2ff',
NOW()
)Разница между двумя датами
DATEDIFF(date2, date1)SELECT DATEDIFF(
NOW(),
'2021-12-14'
)Если сегодня 16 декабря, то результат - 2
SELECT DATEDIFF(
'2021-12-14',
NOW()
)Если сегодня 16 декабря, то результат - -2
Работа с меткой времени (timestamp)
Метка времени - это кол-во секунд, прошедших с 1 января 1970 до определённого момента - даты и времени.
Любую дату можно преобразовать в метку времени и обратно.
UNIX_TIMESTAMP(date)
FROM_UNIXTIME(timestamp)Так легче посчитать кол-во секунд, минут, часов, дней и т.д между двумя датами. Делается это обычными делениями и умножениями на, например, кол-во секунд в минутах, часах и т.д
Агрегатные функции
COUNT(\*)
SELECT COUNT(*)
FROM `good`SELECT COUNT(DISTINCT `name`)
FROM `good`SUM(field)
SELECT SUM(`count`)
FROM `good`Так можно узнать общее кол-во товаров на складе
Или общую стоимость всех товаров:
SELECT SUM(`price` * `count`)
FROM `good`В SUM() тоже можно вкладывать другие операторы:
SELECT SUM(
IF(`count` < 50, 1, 0)
)
FROM `good`MIN(field), MAX(field), AVG(field)
AVG(field) (average - средний, усредненный) выводит среднее значение среди записей в поле field
SELECT
MIN(`price`) minPrice,
MAX(`price`) maxPrice,
AVG(`price`) avgPrice
FROM `good`Результат:
minPrice | maxPrice | avgPrice |
|---|---|---|
| 137 | 997 | 359.8794 |
| На этом агрегатные функции не заканчиваются, я описал только основные. |
Фильтрация после группировки, оператор HAVING
Группировка c HAVING
HAVING используется для фильтрации результата GROUP BY по заданным логическим условиям.
Чем отличается WHERE от HAVING?
Во-первых, в HAVING и только в нём можно писать условия по агрегатным функциям (SUM, COUNT, MAX, MIN и т. д.). WHERE выполняется до формирования групп GROUP BY.
Главное отличие HAVING от WHERE в том, что в HAVING можно наложить условия на результаты группировки, потому что порядок исполнения запроса устроен таким образом, что на этапе, когда выполняется WHERE, ещё нет групп, а HAVING выполняется уже после формирования групп.
SELECT
`category_id`,
COUNT(*) `count`
FROM `good`
GROUP BY `category_id`
HAVING `count` < 50или (эквивалентные запросы):
SELECT
`category_id`,
COUNT(*) `count`
FROM `good`
GROUP BY `category_id`
HAVING COUNT(*) < 50Несколько условий
SELECT
`category_id`,
COUNT(*) `count`
FROM `good`
GROUP BY `category_id`
HAVING `count` < 50 OR
`count` > 300Скорость выполнения запросов, индексы
От чего зависит скорость?
- Размер таблицы
- Скорость поиска
Как происходит поиск в таблице?
- Перебором
- “По-умному”
Поиск «по-умному»
Пример: бинарный поиск:
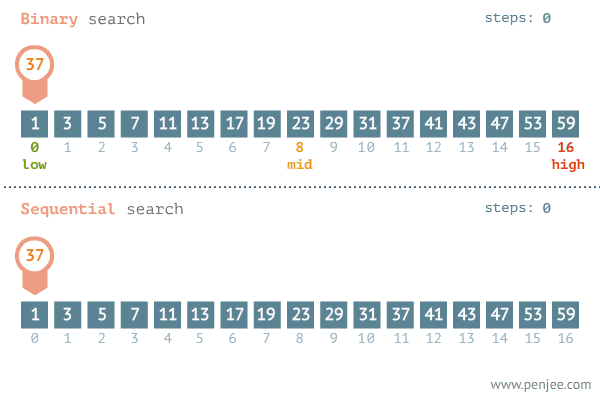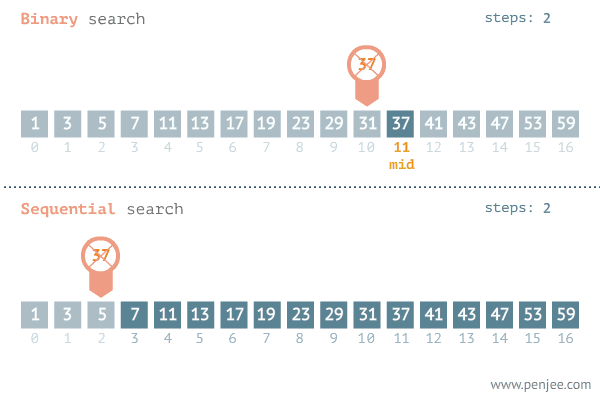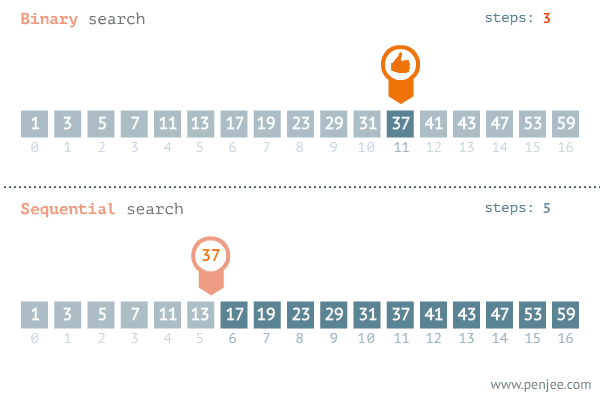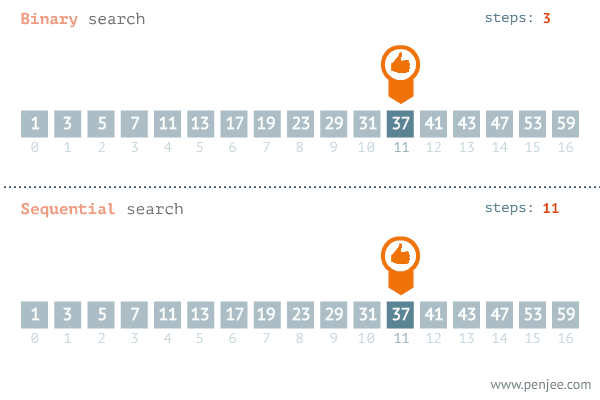
Скорость работы бинарного поиска зависит от кол-ва данных. Например, чтобы найти среди 1 млн, к примеру, чисел понадобится, в худшем случае, 20 операций:
1000000
500000
250000
125000
62500
31250
15625
7812
3906
1953
976
488
244
122
61
30
15
7
3
1
Для ускорения поиска в MySQL есть индексы (ключи).
Типы индексов (ключей) в MySQL
- BTREE (binary tree)
Для поиска по диапазонам - HASH
Для поиска по совпадениям
Установка индексов (ключей)
При создании таблицы:
CREATE TABLE `good_type`(
`id` INT NOT NULL AUTO_INCREMENT,
`name` VARCHAR(255),
PRIMARY KEY(`id`)
);Установка индекса в уже существей таблице:
ALTER TABLE `good`
ADD PRIMARY KEY (`id`);Первичный ключ
Задается для идентификации записей (поля id, грубо говоря):
ALTER TABLE `good`
ADD PRIMARY KEY (`id`);Обычный ключ
ALTER TABLE `good`
ADD KEY (`category_id`);Уникальный ключ
Задается для предотвращения дублирования записей:
ALTER TABLE `good_type`
ADD UNIQUE (`code`);Отличия UNIQUE от PRIMARY KEY
PRIMARY KEY | UNIQUE | |
|---|---|---|
| Используется для идентификации записей | Да | Нет |
Может быть одно значение NULL | Нет | Да |
| Может быть несколько в таблице | Нет | Да |
Индексы (ключи)
По одному полю
ALTER TABLE `good`
ADD KEY (`category_id`);По нескольким полям
ALTER TABLE `order_status_change`
ADD KEY (
`src_status_id`,
`dst_status_id`
);С указанием длины
ALTER TABLE `good`
ADD KEY (`name`(30));Связи, внешние ключи и ограничения
Нарушение целостности данных
Наличие ссылок на отсутствующие записи в других таблицах.
Решение: установка связей с ограничениями.
Установка связи “one-to-many”
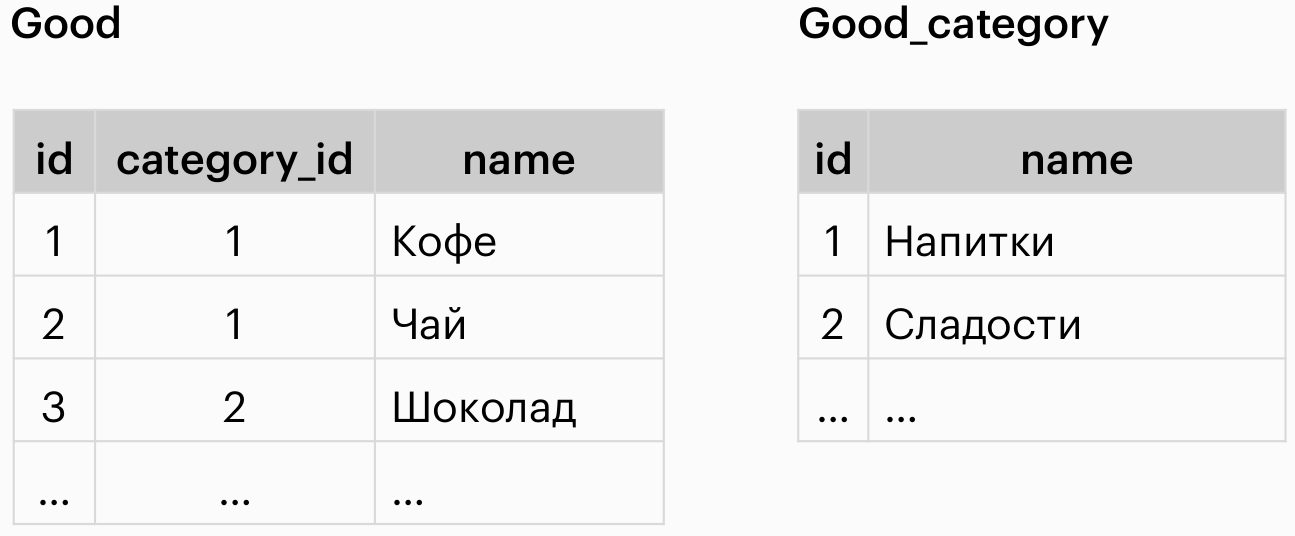
ALTER TABLE `good`
ADD FOREIGN KEY (`category_id`)
REFERENCES `good_category`(`id`);REFERENCES обозначает связь между таблицами. FOREIGN KEY (внешний ключ) как раз и позволяет пользоваться REFERENCES.
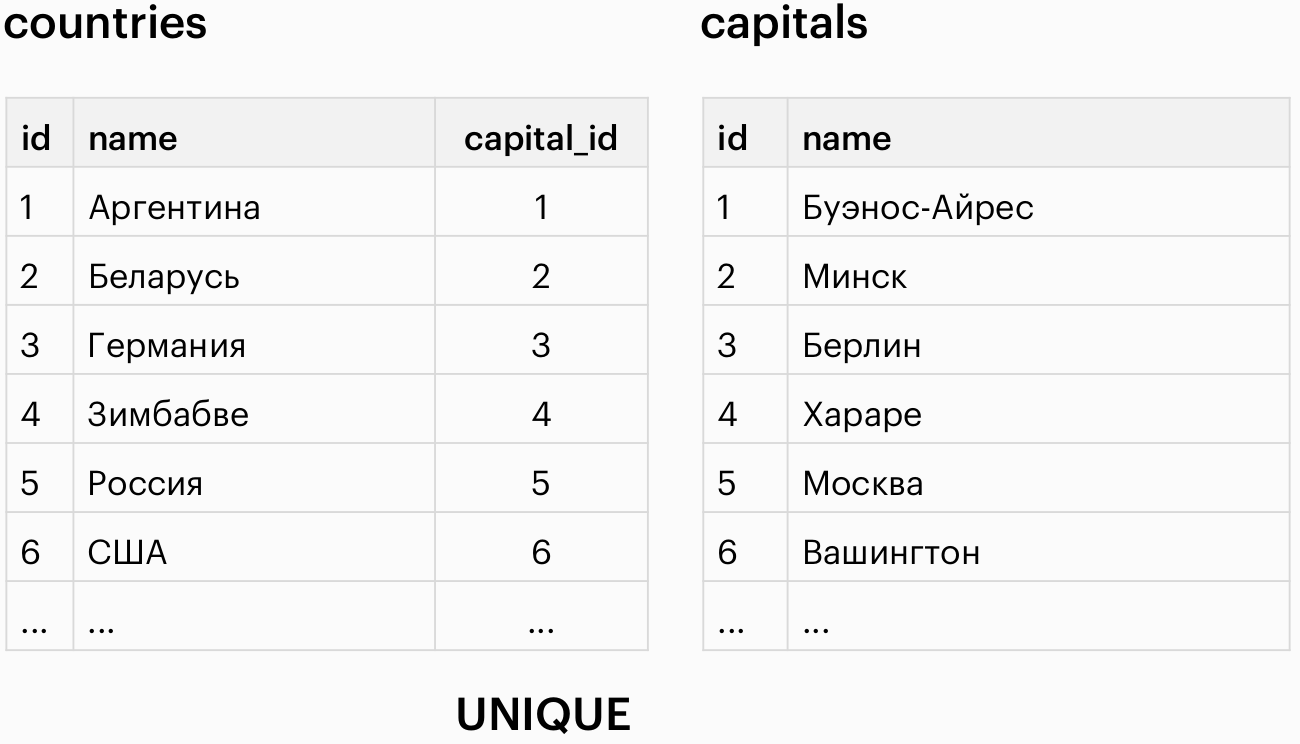
Установка связи “one-to-one”
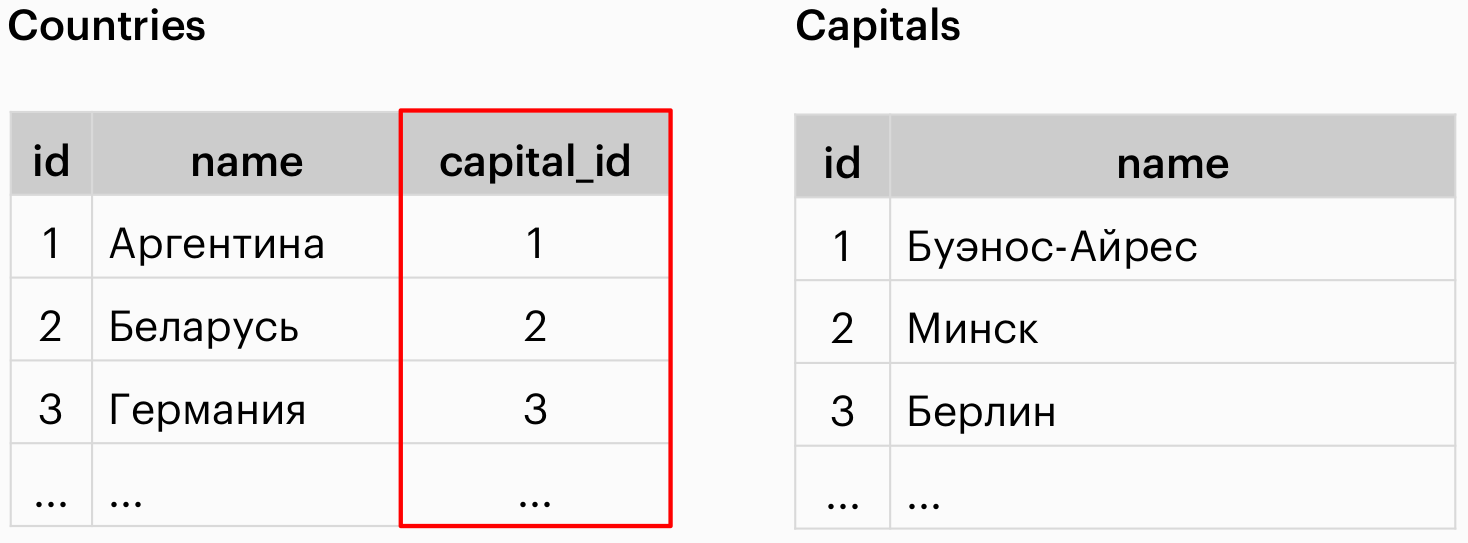
#Установка уникального ключа
ALTER TABLE `countries` ADD UNIQUE (`capital_id`);
#Установка внешнего ключа
ALTER TABLE `countries`
ADD FOREIGN KEY (`capital_id`)
REFERENCES `capitals`(`id`);capital_id должен быть уникальным (если считаем, что у каждой страны только одна столица), поэтому полю capital_id задается ключ UNIQE
Установка связи “many-to-many”
CREATE TABLE `book2order`(
`id` INT NOT NULL AUTO_INCREMENT,
`book_id` INT NOT NULL,
`order_id` INT NOT NULL,
PRIMARY KEY (`id`),
FOREIGN KEY (`book_id`)
REFERENCES `books`(`id`),
FOREIGN KEY (`order_id`)
REFERENCES `orders`(`id`),
UNIQUE(`book_id`, `order_id`)
);В такой таблице должен быть установлен первичный ключ, внешние ключи и уникальный индекс, чтобы не дублировались связи.
Именование ключей и ограничений
ALTER TABLE `book2order`
ADD CONSTRAINT `book2order_fk_1`
FOREIGN KEY (`order_id`)
REFERENCES `order` (`id`),
ADD CONSTRAINT `book2order_fk_2`
FOREIGN KEY (`book_id`)
REFERENCES `book` (`id`);C помощью CONSTRAINT можно задать имя ключам или ограничениям для упрощения доступа к ним в будущем по имени:
ALTER TABLE `book2order`
DROP INDEX `book2order_fk_2`;Обеспечение целостности данных
Как обеспечивать целостность данных при их изменении или удалении?
ALTER TABLE `good`
ADD FOREIGN KEY (`category_id`)
REFERENCES `good_category`(`id`);
ON DELETE SET NULL
ON UPDATE NO ACTION;При удалении записи из таблицы good_category в таблице good в соответствующих записях в поле category_id будет значение NULL.
При изменении поля id в таблице good_category произойдёт ошибка в случае, если в таблице good есть хотя бы одна запись, которая ссылается на этот id в таблице good_category.
Действия при нарушении целостности
| Ключевое слово | Действие |
|---|---|
RESTRICTNO ACTION(по умолчанию) | Ограничение действия, если оно нарушает целостность данных |
CASCADE | Каскадное удаление или изменение связанных записей |
SET NULL | Установка NULL в поле, которые после выполнения действия будет ссылатьтся на несуществующую запись |
Вложенные запросы
Задача: Разделить общие стоимости на две группы
- Сначала нужно посчитать эти общие стоимости:
SELECT
`id`,
(`count` * `price`) totalPrice
FROM `good`
GROUP BY `id`- Разделить стоимости на общие группы с помощью вложенного запроса (прошлого):
SELECT
SUM(IF(totalPrice > 10000, totalPrice, 0))
highPriceTotal,
SUM(IF(totalPrice <= 10000, totalPrice, 0))
lowPriceTotal
FROM (
SELECT
`id`,
(`count` * `price`) totalPrice
FROM `good`
GROUP BY `id`
) t #алиас таблицыРезультат:
highPriceTotal | lowPriceTotal |
|---|---|
| 98532703 | 453541 |
Вложенные запросы (подзапросы) в условиях
Задача: вывести общие стоимости товаров из категорий, в которых более пятидесяти наименований.
SELECT
`id`,
(`count` * `price`) totalPrice
FROM `good`
WHERE `category_id` IN(
SELECT `category_id`
FROM `good`
GROUP BY `category_id`
HAVING COUNT(*) > 50
)
GROUP BY `id`Результат вложенного запроса:

Вообще, вложенные запросы требовательны к ресурсам чисто из-за того, что при таком запросе каждый раз будет выполнятся сначала вложенный запрос и уже над ним - все остальные приколы.
Если результат вложенного запроса не меняется, то лучше просто один раз выполнить этот запрос и его результат записать в IN(). Так можно избежать ненужных вложенных запросов.
SELECT `category_id`
FROM `good`
GROUP BY `category_id`
HAVING COUNT(*) > 50Получили данные один раз и работаем с ними:
SELECT
`id`,
(`count` * `price`) totalPrice
FROM `good`
WHERE `category_id` IN(43, 261, 4429)
GROUP BY `id`Структурные запросы
Запросы управления базами данных
Показать все БД
SHOW DATABASES;Использовать / переключиться на / выбрать БД
USE `databaseName`;Создать БД
CREATE DATABASE `databaseName`;Удалить БД
DROP DATABASE `databaseName`;Запросы управления таблицами
Показать все таблицы в текущей/активной БД
SHOW TABLES;Показать структуру таблицы в текущей/активной БД
DESCRIBE `tableName`;Создать таблицу
CREATE TABLE `good_type`(
`id` INT NOT NULL AUTO_INCREMENT,
`sort_index` INT,
`name` VARCHAR(255),
PRIMARY KEY(`id`)
);Удалить поле и создать новое в таблице
ALTER TABLE `good_type`
DROP COLUMN `name`,
ADD `code` TEXT NOT NULL
AFTER `id`;Удаление всех строк в таблице (Быстрая очистка)
TRUNCATE `tableName`;Удаление таблицы
DROP TABLE `tableName`;Представления
Представления - виртуальные таблицы, основанные на результате выполнения определённого SQL-запроса.
Пример задачи
Отдельно обращаться к списку заканчивающихся или закончившихся товаров - товаров, которых на складе осталось менее 10-ти штук - с ценой более 200 рублей за штуку.
SQL-запрос
SELECT * FROM `good`
WHERE `count` < 10 AND `price` > 200;Представление
CREATE VIEW `ending_goods` AS
SELECT * FROM `good`
WHERE `count` < 10 AND `price` > 200;Использование
SELECT * FROM `ending_goods`;Создание или замена
CREATE OR REPLACE VIEW `ending_goods` AS
SELECT * FROM `good`
WHERE `count` < 10 AND `price` > 200;Удаление представления
DROP VIEW `ending_goods`;