Задание 1
Что нужно сделать
Соберите следующие метрики:
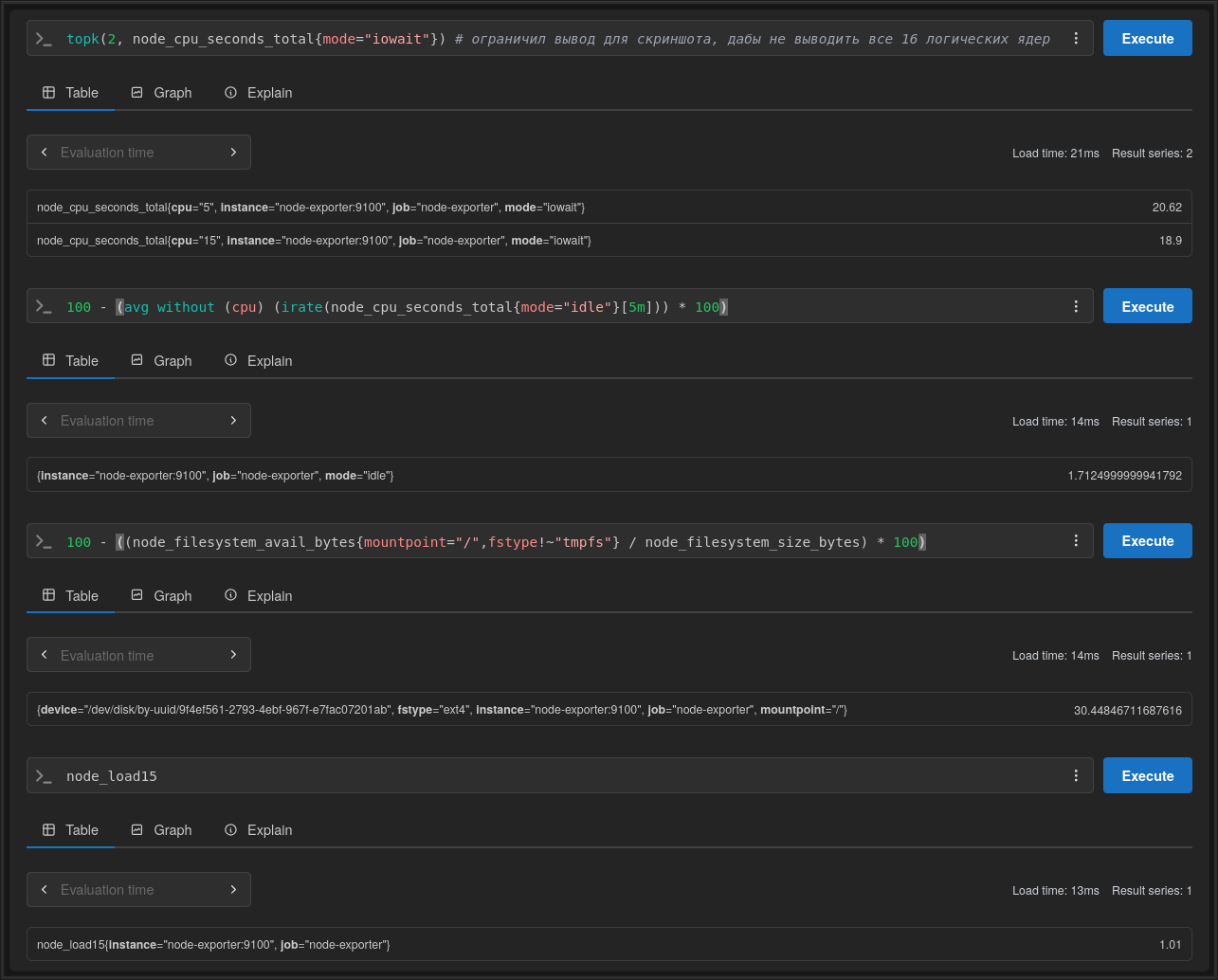
node_cpu_seconds_total— режим iowait.node_cpu_seconds_total— загрузка процессора в процентах. Подсказка: без CPU.node_filesystem_avail_bytes— mountpoint/, исключить device tmpfs. Занятое место в процентах.node_loadза 15 минут (примечание: тут есть подвох).
Метрики:
node_cpu_seconds_total{mode="iowait"}
100 - (avg without (cpu) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
100 - ((node_filesystem_avail_bytes{mountpoint="/",fstype!~"tmpfs"} / node_filesystem_size_bytes) * 100)
node_load15Тоже самое в Prometheus WebUI:
Задание 2
Что нужно сделать
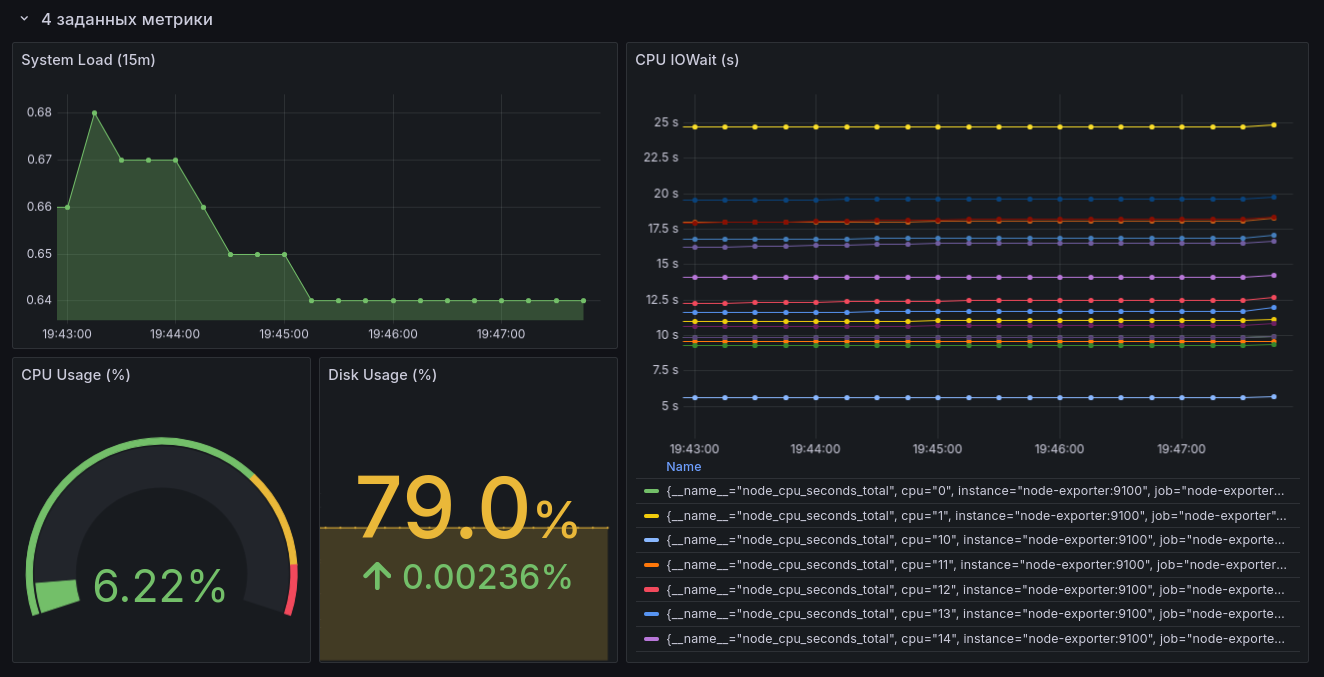
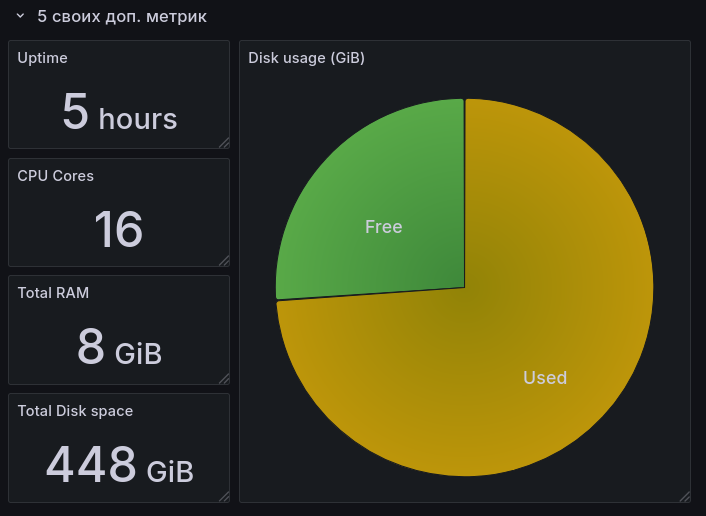
Используя Grafana, прикрутите визуализацию для всех метрик, что мы указали выше, плюсом добавьте свои, на ваш вкус и цвет. Пять штук будет вполне достаточно. Чтобы было интереснее, визуализируйте все метрики, используя Stat, Graph, Gauge, Time Series и Pie Chart. Для каких метрик что использовать ― на ваше усмотрение.
Graph и Time Series
Раньше был тип визуализации “Graph”, у которого, как я понимаю, имелся формат “Time Series”, а теперь это просто одна сущность в виде типа визуализации “Time Series” — визуализации под именем “Graph” больше нет.
Использование Slideshow
Dashboard
Data sources
Задание 3
Что нужно сделать
Сделайте четыре алерта:
- Хост получает очень много трафика за минуту. Пусть будет выше 50 Mb/s.
- Загрузка процессора выше 85%.
- У нас упал какой-то таргет
up == 0.- У нас упало ВСЁ.
Configuration
# yaml-language-server: $schema=https://raw.githubusercontent.com/compose-spec/compose-spec/master/schema/compose-spec.json
x-common: &common
networks:
- monitoring
restart: unless-stopped
x-shared-env: &shared-env
TZ: "Europe/Moscow"
name: monitoring-practical-work
services:
alertmanager:
image: prom/alertmanager:v0.28.0
container_name: alertmanager
depends_on:
- envsubst
- prometheus
volumes:
- ./alertmanager:/etc/alertmanager
environment: *shared-env
ports:
- "127.0.0.1:9093:9093"
command:
- --config.file=/etc/alertmanager/alertmanager.yml
- --log.level=debug
<<: *common
# Source: https://github.com/mrnetops/fastly-dashboards/blob/90e51227356292cc1f0714b5487bdb873b9bdcdf/docker-compose.yml#L16-L21
envsubst:
image: bhgedigital/envsubst:v1.0-alpine3.6
container_name: envsubst
volumes:
- ./alertmanager:/mnt
env_file: .env
command: sh -c "envsubst < /mnt/alertmanager.template.yml > /mnt/alertmanager.yml"
grafana:
image: grafana/grafana:11.5.2
container_name: grafana
depends_on:
- prometheus
volumes:
- grafana-data:/var/lib/grafana
- ./grafana/provisioning/datasources/datasource.yml:/etc/grafana/provisioning/datasources/datasource.yml
- ./grafana/provisioning/dashboards/dashboards.yml:/etc/grafana/provisioning/dashboards/dashboards.yml
- ./grafana/provisioning/dashboards/json:/var/lib/grafana/dashboards
environment:
<<: *shared-env
GF_AUTH_ANONYMOUS_ENABLED: "true"
GF_AUTH_ANONYMOUS_ORG_ROLE: "Admin"
ports:
- "127.0.0.1:3000:3000"
<<: *common
loki:
image: grafana/loki:3.4.2
container_name: loki
volumes:
- ./loki/loki-config.yml:/etc/loki/loki-config.yml:ro
environment: *shared-env
ports:
- "127.0.0.1:3100:3100"
command: -config.file=/etc/loki/loki-config.yml
<<: *common
node-exporter:
image: prom/node-exporter:v1.9.0
container_name: node-exporter
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
environment: *shared-env
ports:
- "127.0.0.1:9100:9100"
command:
- --path.procfs=/host/proc
- --path.sysfs=/host/sys
- --collector.filesystem.ignored-mount-points
- ^/(sys|proc|dev|host|etc|rootfs/var/lib/docker/containers|rootfs/var/lib/docker/overlay2|rootfs/run/docker/netns|rootfs/var/lib/docker/aufs)($$|/)
<<: *common
prometheus:
image: prom/prometheus:v3.2.1
container_name: prometheus
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml:ro
- ./prometheus/alerts.yml:/etc/prometheus/alerts.yml
- prometheus-data:/prometheus
environment: *shared-env
ports:
- "127.0.0.1:9090:9090"
command:
- --config.file=/etc/prometheus/prometheus.yml
- --storage.tsdb.path=/prometheus/data
- --web.enable-lifecycle
<<: *common
promtail:
image: grafana/promtail:3.4.2
container_name: promtail
depends_on:
- loki
volumes:
- ./loki/promtail-config.yml:/etc/promtail/promtail-config.yml:ro
- /var/log:/var/log:ro
environment: *shared-env
command: -config.file=/etc/promtail/promtail-config.yml
<<: *common
networks:
monitoring:
driver: bridge
volumes:
prometheus-data: {}
grafana-data: {}global:
resolve_timeout: 5m
telegram_api_url: 'https://api.telegram.org'
templates:
- /etc/alertmanager/templates/telegram.tmpl
receivers:
# Source: https://prometheus.io/docs/alerting/latest/configuration/#telegram_config
- name: 'telegram'
telegram_configs:
- chat_id: ${TELEGRAM_CHAT_ID}
bot_token: ${TELEGRAM_BOT_TOKEN}
parse_mode: 'HTML'
message: '{{ template "telegram.message". }}'
route:
group_by: ['alertname']
group_wait: 15s
group_interval: 30s
repeat_interval: 4h
receiver: telegram
routes:
- receiver: telegram
continue: true
matchers:
- severity =~ "warning|critical"groups:
- name: "Main rules"
rules:
- alert: HighIncomingTraffic
expr: sum by (instance) (rate(node_network_receive_bytes_total{device!~"lo|veth.*|docker.*"}[15s])) / (1024 * 1024) > 50
for: 15s
labels:
severity: warning
annotations:
summary: "High Incoming network Traffic"
description: "Incoming network Traffic > 50 MB/s on {{ $labels.instance }}"
- alert: HighCpuLoad
expr: 100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[1m])) * 100) > 85
for: 5s
labels:
severity: warning
annotations:
summary: "High CPU Load"
description: "CPU Load > 85% on {{ $labels.instance }}"
- alert: TargetDown
expr: up == 0
for: 5s
labels:
severity: critical
annotations:
summary: "Prometheus target is DOWN"
description: "{{ $labels.instance }} is DOWN"
- alert: AllTargetsDown
expr: count by (job) (up) == 0
for: 5s
labels:
severity: critical
annotations:
summary: "All Prometheus targets are DOWN"
description: "Prometheus can't find NONE of the targets"Alert messages
Алерты отправляются напрямую в telegram без посредников-сервисов.
{{ define "telegram.message" }}
{{ range .Alerts }}
{{ if eq .Status "firing" }}
{{ if eq .Labels.severity "critical" }}🚨 <code>{{ .Labels.alertname }}</code> {{ else }}⚠️ <code>{{ .Labels.alertname }}</code>{{ end }}
<b>{{ .Annotations.summary }}</b> on <b>{{ .Labels.instance }}</b>
{{ .Annotations.description }}
{{ else if eq .Status "resolved" }}
✅ <b>RESOLVED</b>: <code>{{ .Labels.alertname }}</code> on <b>{{ .Labels.instance }}</b>
{{ end }}
{{ end }}
{{ end }}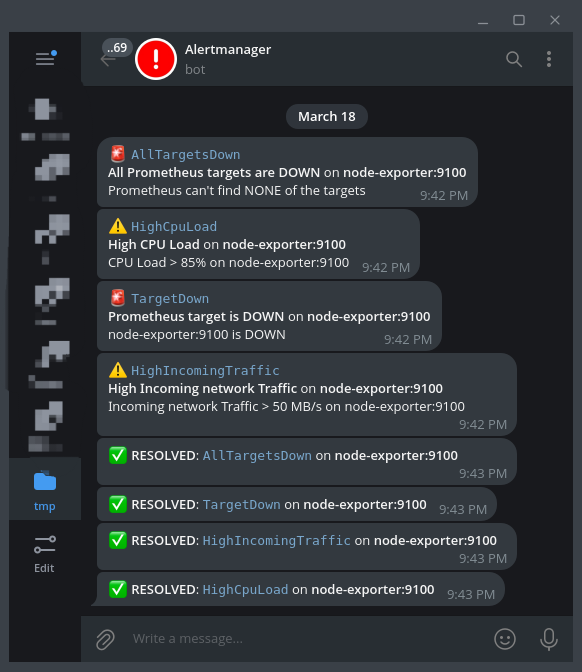
Задание 4
Что нужно сделать
Пускай у нас будет условный интернет-магазин.
- На первом инстансе у нас веб-приложение.
- На втором ― база данных.
- На третьем ― Prometheus, Grafana и так далее.
Разверните систему мониторинга, чтобы за всем этим делом следить.